
最終更新:2026年4月 / 対象バージョン:LangChain 0.3.x / Python 3.11+
1. 結論:最適解はConversationBufferWindowMemory+外部ストア併用
LangChain エージェントにメモリを実装する場合、短期記憶にはConversationBufferWindowMemory(直近k件保持)、長期記憶にはRedis または DynamoDB を組み合わせるアーキテクチャが現場での最適解です。
理由は3つあります。
- コスト制御:Buffer全件保持はトークン爆発を起こす。Window方式でLLM呼び出しコストを抑制できる。
- 本番稼働性:インメモリのみでは再起動時にセッションが消える。外部ストアで永続化が必須。
- スケール対応:Kubernetes Pod が複数起動する環境では、共有ストアなしでセッション整合性を保てない。
「とにかく動かしたい」段階なら ConversationBufferMemory 単体で問題ありません。本番投入するなら Redis 連携まで実装してください。
2. そもそも LangChain エージェントとメモリとは
LangChain エージェントとは
LangChain エージェントは「LLM(大規模言語モデル)が自律的にツールを選択・実行して目標を達成する仕組み」です。単純なQ&Aと違い、Web検索・データベース参照・コード実行などの外部ツールを組み合わせて複雑なタスクをこなします。
メモリとは何をするのか
デフォルトのLLMは「ステートレス」で、毎回の呼び出しが独立しています。メモリ機能は会話履歴・中間結果・ユーザー情報をエージェントに渡すことで「文脈を持った連続した対話」を実現します。
| 種類 | 保持する情報 | 代表クラス |
|---|---|---|
| 短期記憶 | 直近の会話ターン | ConversationBufferWindowMemory |
| 要約記憶 | 過去会話の要約 | ConversationSummaryMemory |
| エンティティ記憶 | 人名・固有名詞 | ConversationEntityMemory |
| 長期記憶(外部) | セッション横断情報 | RedisChatMessageHistory |
3. 仕組みとアーキテクチャ
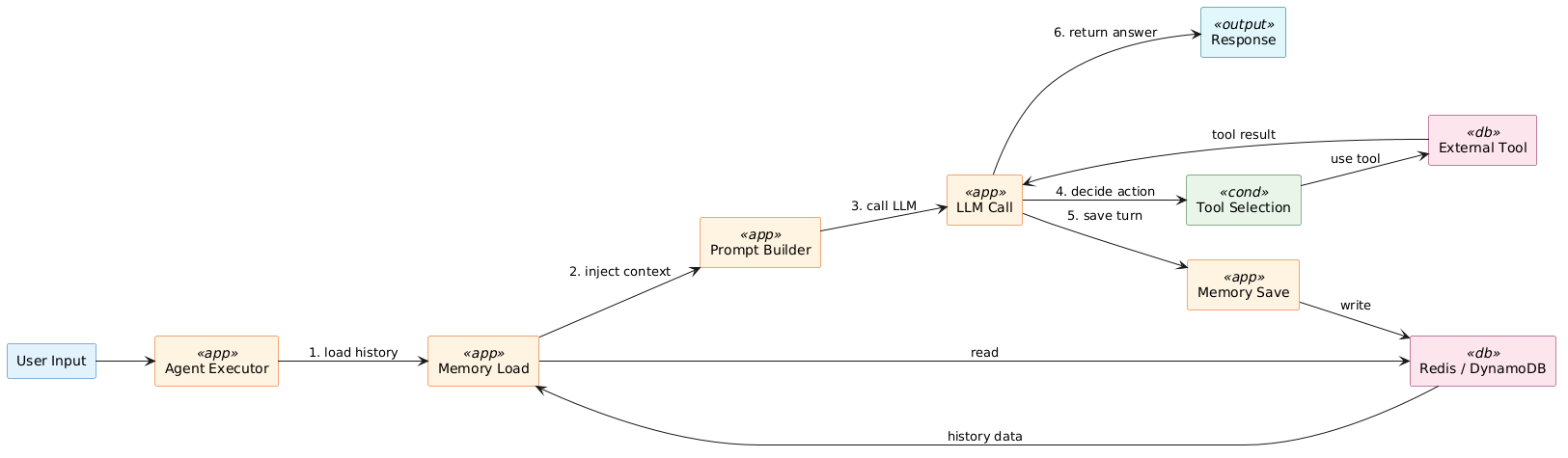
メモリが処理される流れ
ユーザーの入力がエージェントに届いてから回答が返るまで、メモリは「読み込み→プロンプト注入→実行→書き込み」というサイクルで動きます。
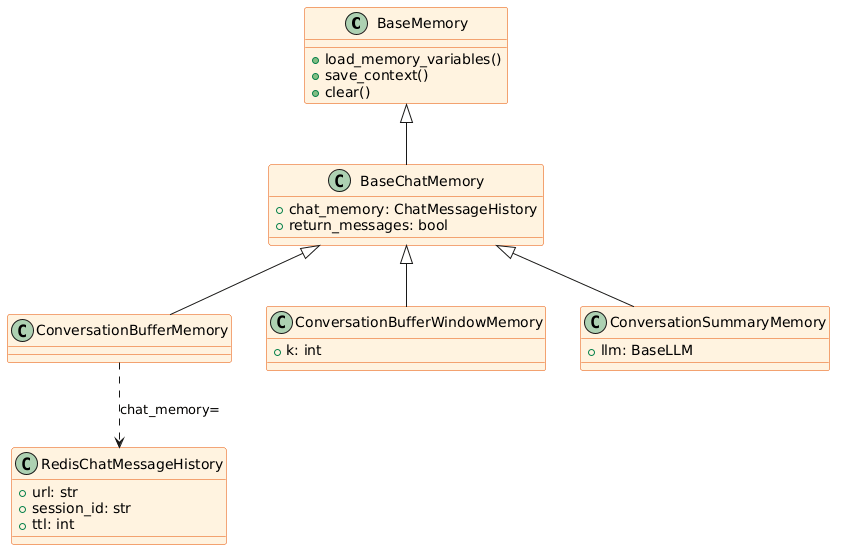
メモリクラスの継承構造
4. 実装手順(ステップ形式)
前提環境
- Python 3.11+
- OpenAI API キー(環境変数
OPENAI_API_KEY) - Redis 7.x(ローカルは Docker で起動)
ディレクトリ構成
langchain-agent-memory/
├── app/
│ ├── __init__.py
│ ├── agent.py # エージェント本体
│ ├── memory.py # メモリ設定
│ └── tools.py # カスタムツール定義
├── tests/
│ └── test_agent.py
├── docker-compose.yml # Redis起動用
├── requirements.txt
└── .env
Step 1:依存パッケージのインストール
# requirements.txt
langchain==0.3.7
langchain-openai==0.2.5
langchain-community==0.3.7
redis==5.1.1
python-dotenv==1.0.1
pip install -r requirements.txtStep 2:Redis を Docker で起動
ファイル名:docker-compose.yml(プロジェクトルート)
version: "3.9"
services:
redis:
image: redis:7-alpine
ports:
- "6379:6379"
command: redis-server --save 60 1 --loglevel warning
volumes:
- redis_data:/data
volumes:
redis_data:docker compose up -d redisStep 3:メモリ設定モジュールの実装
ファイル名:app/memory.py
"""
メモリ設定モジュール
- セッションIDごとにRedisへ会話履歴を永続化
- WindowMemoryで直近k件のみLLMに渡し、トークンコストを抑制
"""
import os
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain.memory import ConversationBufferWindowMemory
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
MEMORY_WINDOW_SIZE = int(os.getenv("MEMORY_WINDOW_SIZE", "10")) # 直近10ターンのみ保持
def get_memory(session_id: str) -> ConversationBufferWindowMemory:
"""
セッションIDに紐づいたメモリオブジェクトを返す。
Redisが落ちている場合はValueErrorを送出する(呼び出し元でハンドリング)。
Args:
session_id: ユーザーまたは会話セッションの一意識別子
Returns:
ConversationBufferWindowMemory: エージェントに渡すメモリオブジェクト
"""
chat_history = RedisChatMessageHistory(
url=REDIS_URL,
session_id=session_id,
ttl=60 * 60 * 24 * 7, # 7日間でセッション自動削除(コスト管理)
)
memory = ConversationBufferWindowMemory(
chat_memory=chat_history,
k=MEMORY_WINDOW_SIZE,
memory_key="chat_history", # プロンプトテンプレートと一致させる
return_messages=True, # HumanMessage/AIMessageオブジェクトで返す
output_key="output", # AgentExecutorの出力キーと一致させる
)
return memory
Step 4:エージェント本体の実装
ファイル名:app/agent.py
"""
LangChain エージェント本体
- OpenAI Functions Agent を使用
- メモリをAgentExecutorに注入してセッション継続性を実現
"""
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tools import tool
from app.memory import get_memory
load_dotenv()
# ---- カスタムツール定義 ----
@tool
def get_weather(city: str) -> str:
"""指定した都市の天気を返す(実務ではOpenWeatherMap API等に差し替え)"""
# 本番ではここをAPIコールに置き換える
return f"{city}の天気:晴れ、気温22℃"
@tool
def calculate(expression: str) -> str:
"""数式を評価して結果を返す"""
try:
result = eval(expression, {"__builtins__": {}}) # 本番はより安全な評価器を使う
return str(result)
except Exception as e:
return f"計算エラー: {e}"
TOOLS = [get_weather, calculate]
# ---- プロンプトテンプレート ----
# chat_history プレースホルダーがメモリの注入ポイント
PROMPT = ChatPromptTemplate.from_messages([
("system", "あなたは親切なアシスタントです。ユーザーの質問に日本語で答えてください。"),
MessagesPlaceholder(variable_name="chat_history"), # ← メモリがここに注入される
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
def create_agent_executor(session_id: str) -> AgentExecutor:
"""
セッションIDに対応したAgentExecutorを生成する。
Args:
session_id: 会話セッションの識別子(例:"user-123")
Returns:
AgentExecutor: 実行可能なエージェント
"""
llm = ChatOpenAI(
model="gpt-4o-mini", # コスト優先。精度重視ならgpt-4oに変更
temperature=0,
api_key=os.getenv("OPENAI_API_KEY"),
)
agent = create_openai_functions_agent(llm=llm, tools=TOOLS, prompt=PROMPT)
memory = get_memory(session_id)
return AgentExecutor(
agent=agent,
tools=TOOLS,
memory=memory,
verbose=True, # デバッグ時はTrueで思考過程を確認
max_iterations=5, # 無限ループ防止
handle_parsing_errors=True, # LLM出力パースエラー時に自動リカバリ
)
# ---- 動作確認用エントリーポイント ----
if __name__ == "__main__":
session = "demo-session-001"
executor = create_agent_executor(session)
questions = [
"東京の天気を教えて",
"さっきの都市は何だったっけ?", # メモリが機能していれば「東京」と答えるはず
"150 * 365 を計算して",
]
for q in questions:
print(f"\n[User]: {q}")
result = executor.invoke({"input": q})
print(f"[Agent]: {result['output']}")
Step 5:環境変数の設定
ファイル名:.env(プロジェクトルート、Gitにコミットしないこと)
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx
REDIS_URL=redis://localhost:6379/0
MEMORY_WINDOW_SIZE=10
Step 6:起動と動作確認
# Redisが起動していることを確認
docker compose ps
# エージェント起動
python -m app.agent
# 期待される出力例:
# [User]: 東京の天気を教えて
# [Agent]: 東京の天気は晴れで、気温は22℃です。
#
# [User]: さっきの都市は何だったっけ?
# [Agent]: さっきお聞きした都市は「東京」です。
2番目の質問で「東京」と正しく答えれば、メモリが機能している確認になります。
5. 実務ユースケース(AWS / Kubernetes 構成)
ユースケース:社内問い合わせ自動化Bot(AWS EKS + ElastiCache構成)
社内のSlack Botとして LangChain エージェントを本番運用する場合、以下のアーキテクチャが現場での標準構成です。
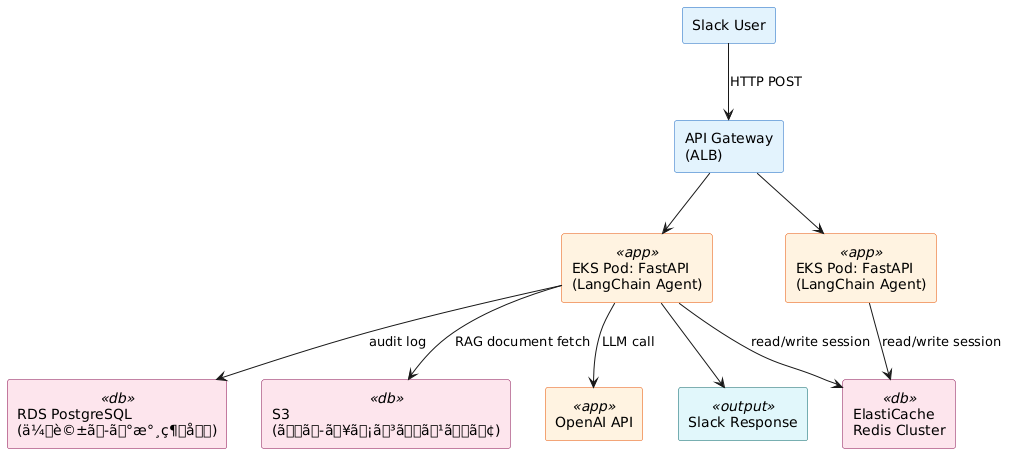
構成のポイント
EKS Pod が複数起動する理由:HPA(Horizontal Pod Autoscaler)でPod数が変動するため、セッションをPod内メモリに持つと別Podにルーティングされた際に履歴が消える。ElastiCache Redis を共有ストアにすることでこの問題を解消します。
RDS に会話ログを二重保存する理由:Redisは高速アクセス向けで、TTL(有効期限)設定により自動削除される。コンプライアンス・監査要件がある場合はRDS(PostgreSQL)に全ターンのログを書き込む必要があります。IAMロールベースのアクセスコントロールでPod→RDS認証を行うのが現場標準です。
S3 + RAG構成:社内ドキュメントをS3に格納し、FAISS または OpenSearch でベクトル検索するRAG(Retrieval-Augmented Generation)と組み合わせることで、エージェントが最新の社内情報を回答に使えるようになります。
Kubernetes マニフェスト抜粋(メモリ関連の環境変数設定)
ファイル名:k8s/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: langchain-agent
spec:
replicas: 2
template:
spec:
containers:
- name: agent
image: your-registry/langchain-agent:latest
env:
- name: REDIS_URL
valueFrom:
secretKeyRef:
name: app-secrets
key: redis-url # ElastiCacheのエンドポイントをSecretで管理
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: app-secrets
key: openai-api-key
- name: MEMORY_WINDOW_SIZE
value: "10"
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
6. メリット・デメリット比較表
メモリ実装方式の比較
| 方式 | コスト | 実装難易度 | 永続性 | スケール対応 | 推奨用途 |
|---|---|---|---|---|---|
| ConversationBufferMemory (インメモリ) | ◎ 無料 | ◎ 簡単 | ✗ 再起動で消滅 | ✗ 単一プロセスのみ | ローカル開発・PoC |
| ConversationBufferWindowMemory (インメモリ) | ◎ 無料 | ◎ 簡単 | ✗ 再起動で消滅 | ✗ 単一プロセスのみ | ローカル開発・トークン節約検証 |
| ConversationSummaryMemory | △ 要約にLLM課金 | ○ 中 | △ バックエンド依存 | △ バックエンド依存 | 長期対話・コンテキスト圧縮 |
| RedisChatMessageHistory | ○ Redis運用費のみ | ○ 中 | ◎ TTL設定可 | ◎ クラスター対応 | 本番・Kubernetes環境 |
| DynamoDBChatMessageHistory | ○ 従量課金 | ○ 中 | ◎ 半永続 | ◎ フルマネージド | AWS本番・サーバーレス |
代替ライブラリとの比較
| ライブラリ | 特徴 | メモリ機能 | 学習コスト | 向いている用途 |
|---|---|---|---|---|
| LangChain | エコシステム最大。ツール・メモリ・チェーンが充実 | ◎ 豊富なメモリクラス | △ APIが複雑 | 複雑なマルチツールエージェント |
| LlamaIndex | RAG特化。ドキュメント検索が強力 | ○ ChatMemoryBuffer | ○ RAG用途は直感的 | ドキュメントQ&A・社内知識検索 |
| AutoGen(Microsoft) | マルチエージェント通信に特化 | ○ 会話履歴管理 | ○ 中程度 | 複数エージェント協調タスク |
7. よくあるエラーと対策
エラー1:output_key の不一致によりメモリが保存されない
事象:エージェントは正常に回答するが、次のターンで直前の会話を覚えていない。verbose=True で確認すると chat_history が常に空のリストになっている。
原因:ConversationBufferWindowMemory の output_key パラメータが AgentExecutor の出力ディクショナリのキー名と一致していないため、LangChainがどのキーを保存すべきか特定できずメモリへの書き込みがスキップされている。
# エラーログ(verbose=Trueのとき)
# Warning: output_key 'output' not found in chain outputs: {'result': '東京の天気は晴れです'}
# Memory not saved.
対策手順
- AgentExecutor の出力キーを確認する:print(executor.invoke({“input”: “test”}).keys()) を実行し、返却されるキー名(例:output or result)を特定する。
- ConversationBufferWindowMemory の output_key を、手順1で確認したキー名と一致させる。
# 修正前(不一致)
memory = ConversationBufferWindowMemory(output_key="result", ...)
# 修正後(AgentExecutorのデフォルト出力キーに合わせる)
memory = ConversationBufferWindowMemory(output_key="output", ...)
エラー2:Redis接続失敗でエージェント起動時にクラッシュする
事象:create_agent_executor() 呼び出し時に例外が発生し、エージェントが起動しない。
redis.exceptions.ConnectionError: Error 111 connecting to localhost:6379. Connection refused.
原因:RedisChatMessageHistory はインスタンス生成時(init)ではなく、初回の読み書き操作時に接続を試みる実装になっているが、環境によってはインスタンス生成時に接続テストが走ることがあり、Redisコンテナが未起動またはネットワーク名が誤っていることで接続拒否が発生している。
対策手順
- Redisが起動しているか確認する:docker compose ps で redis サービスが Up であることを確認。
- 接続URLが正しいか確認する:Kubernetes環境ではサービス名でアクセスするため、redis://redis-service:6379/0 のようにService名を使用する(localhost は不可)。
- 接続失敗時のフォールバック処理をアプリ側に実装する。
import redis
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain.memory import ConversationBufferWindowMemory
def get_memory(session_id: str) -> ConversationBufferWindowMemory:
try:
chat_history = RedisChatMessageHistory(
url=REDIS_URL,
session_id=session_id,
ttl=60 * 60 * 24 * 7,
)
# 接続テスト:実際に読み書きできるか確認
chat_history.messages # 空でもConnectionErrorが出ればここで検知
except redis.exceptions.ConnectionError as e:
# 本番では CloudWatch Logs / Datadog にアラート送信
raise ValueError(f"Redis接続失敗。REDIS_URL={REDIS_URL} を確認してください: {e}")
return ConversationBufferWindowMemory(
chat_memory=chat_history,
k=MEMORY_WINDOW_SIZE,
memory_key="chat_history",
return_messages=True,
output_key="output",
)
エラー3:トークン上限超過でAPIエラーが発生する
事象:長い会話の後半で突然エラーになり、エージェントが応答しなくなる。
openai.BadRequestError: Error code: 400 -
{'error': {'message': "This model's maximum context length is 128000 tokens.
However, your messages resulted in 131500 tokens.", 'type': 'invalid_request_error'}}
原因:ConversationBufferMemory(Window なし)を使用しているため、会話ターンが増えるにつれてプロンプトに注入される chat_history のトークン数が無制限に増加し、モデルのコンテキスト長上限を超えている。
対策手順
- ConversationBufferMemory を ConversationBufferWindowMemory(k=10) に変更し、直近10ターンのみ保持するようにする。
- より長い文脈が必要な場合は ConversationSummaryMemory を使用し、古い会話を要約してトークン数を圧縮する。
- 本番環境では事前にトークン数をカウントするミドルウェアを実装し、閾値を超えたら自動で要約モードに切り替えるロジックを入れる。
from langchain.memory import ConversationSummaryBufferMemory
# SummaryBufferMemory: 直近はそのまま保持、古い分は要約に変換するハイブリッド方式
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=4000, # これを超えたら古い会話を要約
memory_key="chat_history",
return_messages=True,
output_key="output",
)
エラー4:同一session_idへの並列リクエストで会話履歴が混在する
事象:負荷テスト中に「自分が質問していないことへの回答」がユーザーに返ることがある(本番障害レベル)。
原因:非同期処理や並列リクエストで同一 session_id に対して複数のリクエストが同時に save_context() を呼ぶと、Redisへの書き込みが競合し、別ユーザーの会話ターンが混入している。
対策手順
- session_id にユーザーIDとリクエストタイムスタンプを組み合わせ、リクエスト単位でユニークになるよう設計する(例:user-123-20250427-143000)。
- Redis の SET … NX(Not eXists)を使ったセッションロックを実装し、同一セッションへの並列書き込みを防ぐ。
- ステートレスなリクエストが必要な場合は、セッション継続をサーバー側ではなくクライアント側(フロントエンド)で保持するアーキテクチャに変更することも検討する。
8. まとめ:実務でのLangChainエージェントメモリ活用
LangChain エージェントのメモリ実装を本番運用に乗せるためのポイントを整理します。
| フェーズ | 推奨構成 | 理由 |
|---|---|---|
| PoC / ローカル開発 | ConversationBufferWindowMemory(インメモリ) | インフラ不要で即時に動作確認できる |
| ステージング / 小規模本番 | RedisChatMessageHistory + BufferWindowMemory | 永続化・スケール対応・TTL自動削除 |
| AWS 大規模本番 | ElastiCache Redis + DynamoDB(ログ)+ EKS | 可用性・監査要件・オートスケール対応 |
現場エンジニアへの追加アドバイス
- コスト管理:Memory Window サイズ(k値)は小さいほどトークン消費が減る。GPT-4o の場合、k=10 と k=30 では1会話あたりのコストが2〜3倍変わることがある。本番前に必ず負荷テストで計測すること。
- 個人情報とメモリ:メモリには個人情報が含まれる場合がある。Redis の暗号化(TLS + auth)とTTL設定は必須。PII(個人識別情報)をメモリに保存しないようフィルタリングレイヤーを設けることを検討する。
- デバッグ:本番で予期しない回答が出たとき、RDSに保存した会話ログを見ながら再現することが重要。
verbose=TrueのログをCloudWatch Logsへ出力しておくと障害調査が格段に速くなる。 - LangSmith との連携:Anthropic / OpenAI のどちらを使っていても、LangSmith でトレースを有効化するとメモリの読み書きタイミング・トークン数・レイテンシが可視化できる。本番前の最適化に有効。
LangChain エージェントのメモリ実装は「動かす」より「本番で安定させる」ところに難しさがあります。本記事の構成(Window Memory + Redis + EKS)を出発点に、ユースケースに合わせてカスタマイズしてください。


コメント