
「RAGを実装したいけど、ベクトルDBはどれを選べばいい?」──この記事では、Pinecone・Weaviate・Chromaの3つを徹底比較し、プロジェクト規模・予算・運用体制ごとの最適解を示します。コード例・比較表・エラー対策まで網羅した現場目線のガイドです。
1. 結論:まず答えから
選定に迷ったら以下の基準で選んでください:
- Chroma:ローカル開発・PoC・社内ツールなど小規模用途。無料・ゼロ設定で即起動できる。
- Pinecone:本番運用・高トラフィック・インフラ管理を省きたいチーム向けのフルマネージドSaaS。
- Weaviate:Kubernetes上でのセルフホスト運用、ハイブリッド検索(ベクトル+全文)、AWS/GCP連携など高度な要件向け。
⚡ 一言まとめ:「試すならChroma → 本番をすぐ出すならPinecone → 運用をコントロールしたいならWeaviate」の順で検討してください。
2. そもそも何か:RAGとベクトルDBの基礎
2-1. RAG(Retrieval-Augmented Generation)とは
RAG(検索拡張生成)は、LLM(大規模言語モデル)が持つ「知識の鮮度不足・ハルシネーション問題」を補うアーキテクチャです。外部データベースから関連ドキュメントを検索し、その内容をプロンプトに付与してから回答を生成します。
主な構成要素は3つです:
- Embedder(埋め込みモデル):テキストを数値ベクトルに変換(例:OpenAI text-embedding-3-small、Sentence-BERT)
- Vector DB(ベクトルDB):ベクトルを格納し、類似検索(ANN)を高速実行
- LLM(生成モデル):検索結果を文脈として回答を生成
2-2. ベクトルDBとはなにか
ベクトルDBは「意味的に似たデータ」を高速検索するために設計されたデータベースです。従来のRDBやElasticsearchがキーワード完全一致・転置インデックスで検索するのに対し、ベクトルDBはコサイン類似度・ユークリッド距離などを使い「意味の近さ」で検索します。
内部ではHNSW(Hierarchical Navigable Small World)やIVFFlatなどのANN(近似最近傍探索)アルゴリズムを用いて、数千万件のベクトルから数ミリ秒でTop-Kを返します。
3. 仕組み解説:RAGアーキテクチャ
3-1. RAG全体フロー
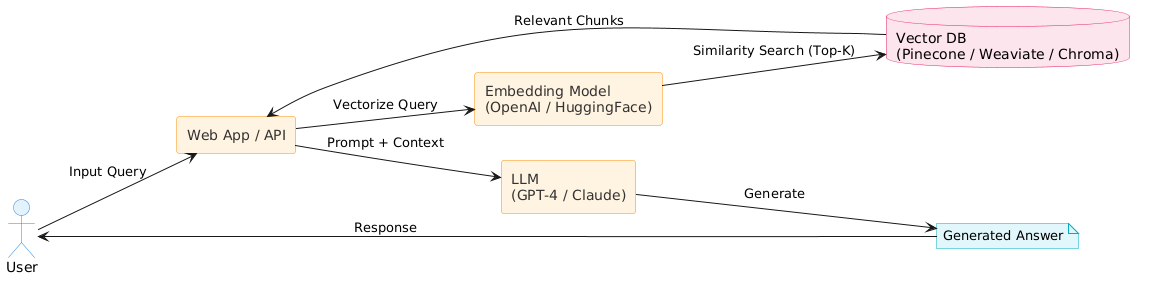
3-2. Indexing(事前データ投入)フロー

3-3. 各DBの内部アーキテクチャ比較
| 項目 | Chroma | Pinecone | Weaviate |
|---|---|---|---|
| インデックス方式 | HNSW(hnswlib) | 独自(HNSW拡張) | HNSW |
| ストレージ | ローカルディスク / メモリ | フルマネージドクラウド | ローカル or クラウド(S3/GCS対応) |
| フィルタリング | メタデータフィルタ(基本) | メタデータフィルタ(高速) | GraphQL + BM25ハイブリッド |
| スケーリング | 単一ノード(水平不可) | 自動スケール(SaaS) | Kubernetes水平スケール |
| 認証 | なし(デフォルト) | APIキー | OIDC / APIキー / RBAC |
| マルチテナント | Collection単位 | Index単位 | Class + テナントAPI |
4. 実装手順:RAGシステムをゼロから構築する
4-1. ディレクトリ構成
rag-vectordb-demo/
├── requirements.txt
├── .env
├── ingest.py # データ投入スクリプト
├── query.py # 検索・生成スクリプト
└── docs/
└── sample.txt # テスト用ドキュメント
4-2. 共通セットアップ
使用言語:Python 3.10+
# requirements.txt
langchain==0.1.20
langchain-openai==0.1.8
langchain-community==0.0.38
openai==1.30.1
chromadb==0.5.0
pinecone-client==3.2.2
weaviate-client==4.6.1
python-dotenv==1.0.1
tiktoken==0.7.0
# .env
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx
PINECONE_API_KEY=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
PINECONE_INDEX_NAME=rag-demo
WEAVIATE_URL=http://localhost:8080
4-3. Chroma:ローカルで即起動
ファイル:ingest_chroma.py
"""
ingest_chroma.py
役割:テキストをChromaDBに投入する
配置:rag-vectordb-demo/ingest_chroma.py
"""
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
load_dotenv()
# 1. ドキュメント読み込み
loader = TextLoader("docs/sample.txt", encoding="utf-8")
docs = loader.load()
# 2. チャンク分割(500トークン・オーバーラップ50)
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
print(f"チャンク数: {len(chunks)}")
# 3. 埋め込み&DB保存
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
db = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db", # ローカルディレクトリに永続化
collection_name="rag_demo"
)
db.persist()
print("Chroma: インデックス作成完了")
ファイル:query_chroma.py
"""
query_chroma.py
役割:ChromaDBから検索し、GPT-4で回答生成
"""
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain.chains import RetrievalQA
load_dotenv()
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
db = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
collection_name="rag_demo"
)
retriever = db.as_retriever(search_kwargs={"k": 4})
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
query = "サンプルドキュメントの内容を教えてください"
result = qa_chain.invoke({"query": query})
print("回答:", result["result"])
print("参照ソース数:", len(result["source_documents"]))
起動・動作確認:
# インデックス作成
python ingest_chroma.py
# 出力例: チャンク数: 12 / Chroma: インデックス作成完了
# 検索クエリ実行
python query_chroma.py
# 出力例: 回答: サンプルドキュメントには...
4-4. Pinecone:フルマネージド本番構成
ファイル:ingest_pinecone.py
"""
ingest_pinecone.py
役割:テキストをPineconeに投入する
前提:Pineconeダッシュボードでインデックス作成済み(dimensions=1536, metric=cosine)
"""
import os
from dotenv import load_dotenv
from pinecone import Pinecone
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import PineconeVectorStore
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
load_dotenv()
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
index_name = os.environ["PINECONE_INDEX_NAME"]
loader = TextLoader("docs/sample.txt", encoding="utf-8")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Pineconeに一括upsert(バッチサイズ100が推奨)
vectorstore = PineconeVectorStore.from_documents(
documents=chunks,
embedding=embeddings,
index_name=index_name,
namespace="rag_demo" # 用途別に名前空間を分ける
)
print(f"Pinecone: {len(chunks)}件をupsert完了 → index: {index_name}")
4-5. Weaviate:Kubernetes / Docker本番構成
# docker-compose.yml(ローカルWeaviate起動)
version: '3.8'
services:
weaviate:
image: semitechnologies/weaviate:1.25.1
ports:
- "8080:8080"
- "50051:50051"
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_MODULES: 'text2vec-openai,generative-openai'
OPENAI_APIKEY: "${OPENAI_API_KEY}"
CLUSTER_HOSTNAME: 'node1'
volumes:
- weaviate_data:/var/lib/weaviate
volumes:
weaviate_data:
"""
ingest_weaviate.py
役割:テキストをWeaviateに投入する
前提:docker-compose up -d でWeaviate起動済み
"""
import os
import weaviate
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Weaviate
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
load_dotenv()
client = weaviate.connect_to_local(host="localhost", port=8080)
loader = TextLoader("docs/sample.txt", encoding="utf-8")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Weaviate.from_documents(
documents=chunks,
embedding=embeddings,
client=client,
index_name="RagDemo", # Weaviateのクラス名はUpperCamelCase
text_key="content",
by_text=False
)
print(f"Weaviate: {len(chunks)}件を投入完了")
client.close()
起動確認:
# WeaviateのDockerコンテナ起動
docker-compose up -d
# ヘルスチェック
curl http://localhost:8080/v1/.well-known/ready
# 出力: {}
# スキーマ確認
curl http://localhost:8080/v1/schema
5. 実務例:現場ユースケース
5-1. 社内ナレッジ検索(Chroma + LangChain on EC2)
小規模チームが社内Confluenceページ・Notionドキュメントを対象にRAGを構築するケースです。
- 構成:EC2 t3.medium + Python + ChromaDB(ローカル永続化) + OpenAI API
- 理由:データが社内限定で外部SaaSに送れない場合、ChromaはEC2内で完結するため情報漏洩リスクを抑えられる
- コスト:EC2費用(月$30程度)+ OpenAI APIのみ
- 注意点:EC2再起動後もChromaデータを保持するため、EBSボリュームにpersist_directoryをマウントすること(
/mnt/chroma_dataなど)
5-2. 高トラフィックカスタマーサポートBot(Pinecone + AWS Lambda)
ECサイトのFAQに対してRAGで自動回答するシステムです。
- 構成:API Gateway → AWS Lambda(Python) → Pinecone Serverless → OpenAI GPT-4o
- 理由:Lambda+Pinecone Serverlessはゼロコールドスタート設計で、同時リクエスト1000件でも自動スケール。インフラ担当不要
- コスト目安:Pinecone Serverless(月$0〜$70 リクエスト従量課金) + Lambda(ほぼ無料帯)
- IAM設定:Lambda実行ロールにはOpenAI APIキーをAWS Secrets Managerで管理し、
secretsmanager:GetSecretValue権限を付与すること
# Lambda関数(rag_handler.py)
import json, os, boto3
from pinecone import Pinecone
from openai import OpenAI
def get_secret():
client = boto3.client("secretsmanager", region_name="ap-northeast-1")
return json.loads(client.get_secret_value(SecretId="rag/api-keys")["SecretString"])
def lambda_handler(event, context):
secrets = get_secret()
pc = Pinecone(api_key=secrets["PINECONE_API_KEY"])
oai = OpenAI(api_key=secrets["OPENAI_API_KEY"])
query = json.loads(event["body"])["question"]
# 1. クエリのベクトル化
embed_resp = oai.embeddings.create(input=query, model="text-embedding-3-small")
query_vector = embed_resp.data[0].embedding
# 2. Pineconeで類似検索
index = pc.Index(os.environ["PINECONE_INDEX"])
results = index.query(vector=query_vector, top_k=4, include_metadata=True, namespace="faq")
context_text = "\n\n".join([m["metadata"]["text"] for m in results["matches"]])
# 3. GPT-4oで回答生成
response = oai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "以下のコンテキストのみを使って日本語で回答してください。"},
{"role": "user", "content": f"コンテキスト:\n{context_text}\n\n質問: {query}"}
]
)
return {"statusCode": 200, "body": json.dumps({"answer": response.choices[0].message.content})}
5-3. マルチテナントSaaSのナレッジ管理(Weaviate on Kubernetes)
複数企業(テナント)がそれぞれのドキュメントをRAG検索するSaaS基盤です。
- 構成:EKS(3ノード) + Weaviate Helm Chart + S3オフロード + ALB
- 理由:WeaviateのMulti-tenancy機能でテナントごとにデータを完全分離できる。GraphQLによるハイブリッド検索(BM25 + ベクトル)で検索精度が高い
- Helm設定の要点:
# values.yaml(Weaviate Helm Chart一部抜粋)
replicaCount: 3
resources:
requests:
memory: "4Gi"
cpu: "2"
limits:
memory: "8Gi"
cpu: "4"
persistence:
enabled: true
storageClassName: "gp3"
size: "100Gi"
env:
ENABLE_MODULES: "text2vec-openai"
MULTI_NODE_ENABLED: "true"
6. メリット・デメリット比較表
| 観点 | Chroma | Pinecone | Weaviate |
|---|---|---|---|
| セットアップ難易度 | ⭐ 非常に簡単(pip installのみ) | ⭐⭐ 簡単(APIキー登録のみ) | ⭐⭐⭐ 中程度(Docker/K8s設定必要) |
| スケーラビリティ | ❌ 単一ノード上限あり(数百万ベクトルまで) | ✅ 自動スケール(億単位対応) | ✅ Kubernetes水平スケール(要設定) |
| コスト(月額目安) | 無料(EC2等インフラ費のみ) | Starter無料 / 本番$70〜$500+ | OSS無料 / Cloud版$25〜 |
| 検索方式 | ベクトル類似 + メタデータフィルタ | ベクトル類似 + メタデータフィルタ | ベクトル + BM25ハイブリッド(高精度) |
| データ主権 | ✅ 完全オンプレ可 | ❌ クラウドのみ(AWS us-east-1等) | ✅ セルフホスト可 |
| マルチテナント | △ Collection分離(APIなし) | △ Namespace分離 | ✅ 専用マルチテナントAPI |
| LangChain連携 | ✅ ネイティブサポート | ✅ ネイティブサポート | ✅ ネイティブサポート |
| 本番障害リスク | 🔴 高(単一障害点) | 🟢 低(SLAあり 99.9%) | 🟡 中(K8s設計次第) |
| 監視・ログ | 自前実装が必要 | ダッシュボード標準提供 | Prometheus/Grafana連携可 |
| 向いているシーン | PoC・社内ツール・個人開発 | スタートアップ・高速本番化 | エンタープライズ・マルチテナントSaaS |
代替手段との比較
| 代替手段 | 特徴 | 選ぶべきケース |
|---|---|---|
| pgvector(PostgreSQL拡張) | 既存PGインフラに追加可。SQL操作で親しみやすい。大規模は遅い(HNSWインデックスは最近追加) | 既存DBをRDSで運用中でベクトル検索を足したいだけの場合 |
| Qdrant | Rustで高速・OSS・Dockerで簡単起動。WeaviateとChromaの中間的ポジション | Chromaより速く、Weaviateより簡単な中規模本番環境 |
| OpenSearch(AWS) | AWS標準サービス。k-NN検索とElasticsearchの全文検索を統合できる | AWS統一運用でk-NN+全文ハイブリッドが必要な場合 |
7. よくあるエラーと対策
エラー①:Chromaで「sqlite3.OperationalError: database is locked」
事象:複数プロセスが同時に同じChromaディレクトリを読み書きしようとしているため、SQLite3がロック状態になりデータ投入・検索が失敗する。
# エラーログ例
sqlite3.OperationalError: database is locked
File "/.../chromadb/db/duckdb.py", line 89, in __init__
self._conn = duckdb.connect(...)
原因:ChromaのデフォルトバックエンドはSQLiteを使用しており、同時書き込みをサポートしていない。FastAPIのワーカーを複数起動すると発生する。
対策手順:
- Chromaをクライアント/サーバーモードで起動し、単一プロセスのみDBにアクセスさせる
# Chromaサーバーを別プロセスで起動
chroma run --path ./chroma_db --host 0.0.0.0 --port 8000
# クライアント側コード(query.py)を変更
import chromadb
client = chromadb.HttpClient(host="localhost", port=8000) # ← ローカルではなくHTTPクライアント
collection = client.get_collection("rag_demo")
- FastAPIの場合はlifespan eventで1インスタンスのみ初期化し、
app.state.chromaで共有する
エラー②:Pineconeで「index not found」または「namespace not found」
事象:Pineconeのインデックス名またはnamespaceが環境変数の誤りにより一致せず、検索結果が0件もしくはKeyErrorが返る。
# エラーログ例
pinecone.exceptions.NotFoundException: Index 'rag-demo-prod' not found.
# または検索は成功するが results["matches"] が空配列
{"matches": [], "namespace": "wrong-namespace", "usage": {"read_units": 1}}
原因:upsert時に使ったnamespace="rag_demo"とquery時のnamespaceが不一致になっているため、別パーティションを検索している。
対策手順:
.envのPINECONE_INDEX_NAMEとダッシュボードのIndex名を一致させる- 以下のデバッグコードでindex統計を確認する
from pinecone import Pinecone
import os
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
index = pc.Index(os.environ["PINECONE_INDEX_NAME"])
stats = index.describe_index_stats()
print(stats)
# 正常時の出力例:
# {'dimension': 1536, 'index_fullness': 0.0, 'namespaces': {'rag_demo': {'vector_count': 150}}, ...}
# vector_countが0の場合はupsertが失敗している
- namespaceを定数化してモジュールで一元管理し、ハードコードを排除する
エラー③:WeaviateでKubernetesのOOMKill(メモリ不足)
事象:Weaviateのポッドが大量のベクトルをインデックスロード中にメモリが上限を超え、KubernetesによってOOMKillされてポッドが再起動を繰り返す。
# kubectl describe podで確認
Reason: OOMKilled
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
# kubectl top podsで確認
NAME CPU(cores) MEMORY(bytes)
weaviate-0 1200m 7800Mi ← limitsの8Giに近い
原因:WeaviateはHNSWインデックスをメモリ上に保持する設計であり、ベクトル数×次元数×4バイトのメモリが必要になるため、デフォルトのlimitsでは大規模データセットを処理しきれない。
対策手順:
- ベクトル数から必要メモリを事前に計算する(例:100万件 × 1536次元 × 4byte ≈ 6GB)
- values.yamlのmemory limitsを計算値の1.5倍以上に設定する
# values.yaml
resources:
requests:
memory: "8Gi"
cpu: "2"
limits:
memory: "16Gi" # ← OOMKill後は最低でも現在値の2倍に増やす
cpu: "4"
- HNSWパラメータの
efConstructionとmaxConnectionsを下げてメモリ使用量を削減する
# WeaviateのClass作成時にHNSWパラメータを調整
class_obj = {
"class": "RagDemo",
"vectorIndexConfig": {
"ef": 64, # デフォルト-1(動的)→ 固定値に
"efConstruction": 64, # デフォルト128 → 下げてメモリ削減
"maxConnections": 16 # デフォルト64 → 下げてメモリ削減
}
}
client.schema.create_class(class_obj)
エラー④:OpenAI Embedding APIのRate Limit超過
事象:大量ドキュメントをingest中にOpenAI Embedding APIのTPM(Tokens Per Minute)制限に引っかかり、429エラーが多発してインデックス作成が途中で止まる。
# エラーログ例
openai.RateLimitError: Error code: 429 - {'error': {'message': 'Rate limit reached for
text-embedding-3-small in organization org-xxxx on tokens per min (TPM): Limit 1000000,
Used 998432, Requested 4200.', 'type': 'requests', 'code': 'rate_limit_exceeded'}}
原因:デフォルトのLangChainのfrom_documentsはチャンクを逐次処理しているが、チャンク数が多い場合にTPM上限に達するため、埋め込みAPIが一時的に拒否するレスポンスを返している。
対策手順:
- tenacityライブラリでexponential backoffを実装してリトライする
from tenacity import retry, stop_after_attempt, wait_exponential, retry_if_exception_type
from openai import RateLimitError
@retry(
retry=retry_if_exception_type(RateLimitError),
wait=wait_exponential(multiplier=1, min=4, max=60),
stop=stop_after_attempt(6)
)
def embed_with_retry(texts, embeddings_model):
return embeddings_model.embed_documents(texts)
- チャンクをバッチサイズ100件に分割し、バッチ間で
time.sleep(1)を挿入してTPMを抑制する - OpenAIのTier2以上に課金状態を上げてTPM上限を引き上げる(Tier1: 1M TPM → Tier2: 2M TPM)
8. まとめ:実務でどう使うか
3つのベクトルDBの選定基準を最終整理します:
| フェーズ / 条件 | 推奨DB | 理由 |
|---|---|---|
| PoC・社内ツール・個人開発 | Chroma | pip install + 5行で起動。コスト$0で試せる |
| スタートアップの早期本番リリース | Pinecone | インフラ不要。SLA 99.9%で安心してスケールできる |
| エンタープライズ・マルチテナントSaaS | Weaviate | データ主権・マルチテナントAPI・ハイブリッド検索すべてを満たす |
| 既存PostgreSQL運用中で小規模ベクトル検索を追加 | pgvector | 既存インフラに追加できインフラ変更コストが最小 |
| AWS統一運用 + 全文検索も必要 | OpenSearch kNN | IAM・CloudWatch・S3と統合でき運用の一元化ができる |
現場エンジニアへの最終アドバイス
- まずChromaで動かす:どのDBでもLangChainのインターフェースは同じなので、後から切り替えはほぼ1行の変更です
- Pineconeはコスト管理を忘れずに:Serverlessは従量課金なので、本番前にread_units/write_unitsの上限アラートをAWS CloudWatch Eventsで設定してください
- Weaviateはメモリサイジングが命:本番投入前にデータ量からメモリ計算し、余裕を持ったlimitsを設定してください
- チャンクサイズは試行錯誤が必要:500トークン±50オーバーラップが出発点ですが、ドキュメントの性質(長文技術書 vs 短文FAQ)で最適値は変わります。RAGasなどで評価指標を計測しながら調整してください
RAGの精度は「検索の品質」に大きく依存します。ベクトルDBの選定と同様に、埋め込みモデルの選択・チャンク戦略・リランキング(Cohere Rerank等)も組み合わせて改善することが、現場での実用レベルに到達する近道です。


コメント