
「OpenAI APIのコストが想定の3倍になった」「本番リリース後に請求が跳ね上がった」——これはAI開発現場で頻繁に起きるトラブルです。本記事では、設計段階から組み込める具体的なコスト削減パターンを、実装コード・アーキテクチャ図・比較表とともに解説します。
1. 結論:OpenAI APIコスト削減の最適解
結論から先に述べます。OpenAI APIコストを大幅に削減するための最優先アクション3つはこれです:
- キャッシュ層の導入(同一・類似クエリの再利用)→ 最大60〜70%削減
- モデルのダウングレード設計(用途別にgpt-4o miniを使い分け)→ 最大80%削減
- プロンプト圧縮+バッチ処理(トークン数最小化)→ 10〜30%削減
これらを組み合わせることで、月数十万円規模のAPIコストを数万円台に抑えた事例が現場では実在します。各パターンの詳細を以降で解説します。
2. そもそもOpenAI APIのコスト構造とは
2-1. トークン課金の仕組み
OpenAI APIはトークン単位の従量課金です。1トークンは英語で約4文字、日本語では1〜2文字が目安です。料金は「入力トークン(プロンプト)」と「出力トークン(レスポンス)」に分かれて課金されます。
2025年4月時点の主要モデルの参考単価(1Mトークンあたり):
| モデル | 入力 | 出力 | 用途 |
|---|---|---|---|
| gpt-4o | $2.50 | $10.00 | 高精度・複雑タスク |
| gpt-4o mini | $0.15 | $0.60 | 軽量・高速・低コスト |
| gpt-4.1 | $2.00 | $8.00 | 長文・コーディング |
| gpt-4.1 mini | $0.40 | $1.60 | バランス型 |
gpt-4o miniはgpt-4oと比べて入力コストが約94%安いため、単純な分類・要約・定型応答であれば積極的に採用すべきです。
2-2. コストが爆発する3大原因
- System Promptの肥大化:毎リクエストに長大なsystem promptを送り続ける
- 会話履歴の全量送信:チャット履歴をそのまま全件渡し続ける
- 全クエリをgpt-4oで処理:用途に関係なく最高性能モデルを使う
3. 仕組み解説:コスト最適化アーキテクチャ
3-1. 全体フロー図(PlantUML)

3-2. 主要コスト削減パターン一覧
| パターン | 削減効果 | 実装難易度 | 推奨優先度 |
|---|---|---|---|
| セマンティックキャッシュ | ★★★★★(最大70%) | 中 | 最高 |
| モデルルーティング | ★★★★(最大80%) | 低〜中 | 高 |
| プロンプト圧縮 | ★★★(10〜30%) | 低 | 高 |
| 会話履歴の要約管理 | ★★★(20〜40%) | 中 | 中 |
| Batch API活用 | ★★★(50%固定割引) | 低 | 高(非リアルタイム用途) |
| Prompt Caching | ★★★(最大50%) | 低 | 高 |
4. 実装手順:コスト最適化パターンを実装する
4-1. 環境構成
使用言語:Python 3.11
主要ライブラリ:openai, redis, tiktoken, numpy
ディレクトリ構成:
project/
├── src/
│ ├── llm/
│ │ ├── __init__.py
│ │ ├── router.py # モデルルーティング
│ │ ├── cache.py # セマンティックキャッシュ
│ │ ├── prompt_utils.py # プロンプト圧縮・トークン管理
│ │ └── client.py # OpenAIクライアントラッパー
│ └── main.py
├── requirements.txt
└── .env
requirements.txt:
openai==1.30.5
redis==5.0.4
tiktoken==0.7.0
numpy==1.26.4
python-dotenv==1.0.1
4-2. Step 1:モデルルーティング実装
ファイル名:src/llm/router.py
"""
モデルルーティング:クエリの複雑さに応じてモデルを自動選択する
"""
import tiktoken
from dataclasses import dataclass
@dataclass
class ModelConfig:
name: str
input_cost_per_1m: float # USD per 1M tokens
output_cost_per_1m: float
max_tokens: int
# 2025年4月時点の参考単価
MODEL_REGISTRY = {
"simple": ModelConfig(
name="gpt-4o-mini",
input_cost_per_1m=0.15,
output_cost_per_1m=0.60,
max_tokens=128000
),
"complex": ModelConfig(
name="gpt-4o",
input_cost_per_1m=2.50,
output_cost_per_1m=10.00,
max_tokens=128000
),
}
# 複雑タスクと判定するキーワード
COMPLEX_KEYWORDS = [
"コード生成", "アーキテクチャ", "比較分析", "法律", "医療",
"generate code", "architecture", "compare", "analyze"
]
def select_model(prompt: str, force_model: str | None = None) -> ModelConfig:
"""
プロンプトの内容と長さからモデルを自動選択する。
force_model が指定された場合はそちらを優先。
"""
if force_model:
return MODEL_REGISTRY.get(force_model, MODEL_REGISTRY["simple"])
enc = tiktoken.encoding_for_model("gpt-4o")
token_count = len(enc.encode(prompt))
# 長大プロンプトまたは複雑キーワード含む場合はgpt-4oへ
if token_count > 2000:
return MODEL_REGISTRY["complex"]
for keyword in COMPLEX_KEYWORDS:
if keyword.lower() in prompt.lower():
return MODEL_REGISTRY["complex"]
return MODEL_REGISTRY["simple"]
def estimate_cost(input_tokens: int, output_tokens: int, model: ModelConfig) -> float:
"""APIコールの推定コスト(USD)を返す"""
input_cost = (input_tokens / 1_000_000) * model.input_cost_per_1m
output_cost = (output_tokens / 1_000_000) * model.output_cost_per_1m
return input_cost + output_cost
4-3. Step 2:セマンティックキャッシュ実装
ファイル名:src/llm/cache.py
"""
セマンティックキャッシュ:意味的に類似したクエリのレスポンスをRedisに保存・再利用する
"""
import json
import hashlib
import numpy as np
import redis
from openai import OpenAI
client = OpenAI()
r = redis.Redis(host="localhost", port=6379, decode_responses=True)
CACHE_TTL_SECONDS = 3600 # キャッシュ有効期限(1時間)
SIMILARITY_THRESHOLD = 0.92 # コサイン類似度のしきい値
def get_embedding(text: str) -> list[float]:
"""text-embedding-3-smallでベクトル化(コスト:$0.02/1Mトークン)"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def cosine_similarity(vec_a: list[float], vec_b: list[float]) -> float:
a = np.array(vec_a)
b = np.array(vec_b)
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
def cache_get(query: str) -> str | None:
"""
クエリと意味的に類似したキャッシュエントリを検索する。
しきい値以上の類似度があれば返却(APIコールをスキップ)。
"""
query_vec = get_embedding(query)
keys = r.keys("cache:*")
for key in keys:
entry = json.loads(r.get(key))
similarity = cosine_similarity(query_vec, entry["embedding"])
if similarity >= SIMILARITY_THRESHOLD:
print(f"[CACHE HIT] similarity={similarity:.3f}, key={key}")
return entry["response"]
return None
def cache_set(query: str, response: str) -> None:
"""クエリのベクトルとレスポンスをRedisに保存する"""
embedding = get_embedding(query)
cache_key = "cache:" + hashlib.md5(query.encode()).hexdigest()
entry = {"embedding": embedding, "response": response, "query": query}
r.setex(cache_key, CACHE_TTL_SECONDS, json.dumps(entry))
print(f"[CACHE SET] key={cache_key}")
4-4. Step 3:プロンプト圧縮と会話履歴管理
ファイル名:src/llm/prompt_utils.py
"""
プロンプト圧縮・会話履歴の要約管理
会話履歴を全量保持すると毎リクエストのトークンが増え続けるため、
古い履歴を要約してコンパクトに保つ。
"""
import tiktoken
from openai import OpenAI
client = OpenAI()
MAX_HISTORY_TOKENS = 2000 # 履歴の最大トークン数(超えたら要約)
def count_tokens(messages: list[dict], model: str = "gpt-4o-mini") -> int:
"""メッセージリストのトークン数を計算する"""
enc = tiktoken.encoding_for_model(model)
total = 0
for msg in messages:
total += len(enc.encode(msg.get("content", "")))
total += 4 # role等のオーバーヘッド
return total
def summarize_history(messages: list[dict]) -> str:
"""
古い会話履歴をgpt-4o-miniで要約する。
要約自体のコストは低く抑えられ、以降のリクエストのトークン削減につながる。
"""
history_text = "\n".join(
[f"{m['role']}: {m['content']}" for m in messages]
)
response = client.chat.completions.create(
model="gpt-4o-mini", # 要約は低コストモデルで十分
messages=[
{"role": "system", "content": "以下の会話を3文以内で要約してください。"},
{"role": "user", "content": history_text}
],
max_tokens=200
)
return response.choices[0].message.content
def trim_history(messages: list[dict]) -> list[dict]:
"""
トークン数がMAX_HISTORY_TOKENSを超えた場合、
古い履歴を要約して先頭に1件のsystem要約メッセージとして挿入する。
"""
if count_tokens(messages) <= MAX_HISTORY_TOKENS:
return messages
# 古い半分を要約対象、新しい半分は残す
midpoint = len(messages) // 2
old_messages = messages[:midpoint]
recent_messages = messages[midpoint:]
summary = summarize_history(old_messages)
summary_message = {
"role": "system",
"content": f"[会話要約] {summary}"
}
print(f"[HISTORY TRIMMED] {len(old_messages)}件を要約しました")
return [summary_message] + recent_messages
4-5. Step 4:統合クライアントの実装と動作確認
ファイル名:src/llm/client.py
"""
コスト最適化済みOpenAIクライアントラッパー
キャッシュ → モデルルーティング → プロンプト圧縮 を統合する
"""
from openai import OpenAI
from .router import select_model, estimate_cost
from .cache import cache_get, cache_set
from .prompt_utils import trim_history, count_tokens
client = OpenAI()
def chat(
user_message: str,
history: list[dict] | None = None,
system_prompt: str = "You are a helpful assistant.",
use_cache: bool = True
) -> dict:
"""
Returns:
dict: {
"response": str,
"model_used": str,
"tokens_used": int,
"estimated_cost_usd": float,
"cache_hit": bool
}
"""
history = history or []
# 1. キャッシュ確認
if use_cache:
cached = cache_get(user_message)
if cached:
return {
"response": cached,
"model_used": "cache",
"tokens_used": 0,
"estimated_cost_usd": 0.0,
"cache_hit": True
}
# 2. モデル選定
model_config = select_model(user_message)
# 3. 会話履歴圧縮
trimmed_history = trim_history(history)
# 4. メッセージ構築
messages = [
{"role": "system", "content": system_prompt},
*trimmed_history,
{"role": "user", "content": user_message}
]
# 5. API呼び出し
response = client.chat.completions.create(
model=model_config.name,
messages=messages,
max_tokens=1024
)
result_text = response.choices[0].message.content
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
cost = estimate_cost(input_tokens, output_tokens, model_config)
# 6. キャッシュ保存
if use_cache:
cache_set(user_message, result_text)
return {
"response": result_text,
"model_used": model_config.name,
"tokens_used": input_tokens + output_tokens,
"estimated_cost_usd": cost,
"cache_hit": False
}
動作確認方法:
# Redisを起動(Docker利用の場合)
docker run -d -p 6379:6379 redis:7-alpine
# 依存パッケージのインストール
pip install -r requirements.txt
# 動作確認
python -c "
from src.llm.client import chat
# 1回目:APIコールあり
result = chat('OpenAIのgpt-4oとgpt-4o miniの違いは?')
print(f'Model: {result[\"model_used\"]}, Cost: \${result[\"estimated_cost_usd\"]:.6f}, Cache: {result[\"cache_hit\"]}')
# 2回目:類似クエリでキャッシュヒット
result2 = chat('gpt-4oとgpt-4o miniはどう違う?')
print(f'Model: {result2[\"model_used\"]}, Cost: \${result2[\"estimated_cost_usd\"]:.6f}, Cache: {result2[\"cache_hit\"]}')
"
期待される出力:
[CACHE SET] key=cache:3a9f1b...
Model: gpt-4o-mini, Cost: $0.000023, Cache: False
[CACHE HIT] similarity=0.957, key=cache:3a9f1b...
Model: cache, Cost: $0.000000, Cache: True
4-6. Batch API活用(非リアルタイム処理)
チャットではなくバッチ分類・要約など即時応答が不要な用途では、Batch APIを使うと50%の固定割引が受けられます。
ファイル名:src/llm/batch_submit.py
"""
Batch API:即時性不要な処理を一括送信してコストを50%削減する
処理完了まで最大24時間かかるため、翌日バッチ集計などに適している
"""
import json
from openai import OpenAI
client = OpenAI()
def submit_batch(requests: list[dict], description: str = "batch job") -> str:
"""
requests: [{"custom_id": "req-1", "prompt": "テキスト"}, ...]
Returns: batch_id
"""
# JSONL形式でリクエストファイルを作成
batch_lines = []
for req in requests:
batch_lines.append(json.dumps({
"custom_id": req["custom_id"],
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": req["prompt"]}],
"max_tokens": 512
}
}))
jsonl_content = "\n".join(batch_lines).encode()
batch_file = client.files.create(
file=("batch_input.jsonl", jsonl_content, "application/jsonl"),
purpose="batch"
)
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"description": description}
)
print(f"Batch submitted: {batch.id}")
return batch.id
5. 実務例:AWS・Kubernetes環境での本番運用パターン
5-1. AWSでのセマンティックキャッシュ構成
本番環境ではRedisをAmazon ElastiCache(Redis互換)で運用します。ElastiCacheはマルチAZ構成でキャッシュの可用性を確保しつつ、IAMロールによるアクセス制御も実現できます。
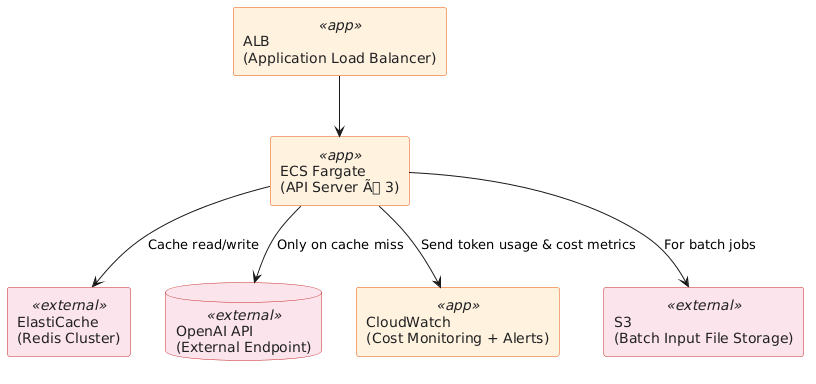
AWS構成のポイント:
- IAM:ECS TaskロールにSecretsManagerの読み取り権限のみ付与し、APIキーをハードコードしない
- ElastiCache:cluster modeでシャーディングし、高スループットのキャッシュ検索に対応
- CloudWatch:カスタムメトリクスでトークン消費量・コストを可視化し、日次予算アラートを設定
- NAT Gateway:ECS FargateからOpenAI APIへのアウトバウンド通信を管理(コスト:転送量課金に注意)
5-2. Kubernetesでの運用パターン
Kubernetes(EKS)環境では、OpenAI APIキーをSecretとして管理し、HPA(Horizontal Pod Autoscaler)でトラフィックに応じたスケーリングを実現します。
# k8s/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: llm-api-server
spec:
replicas: 3
selector:
matchLabels:
app: llm-api-server
template:
metadata:
labels:
app: llm-api-server
spec:
containers:
- name: api-server
image: your-ecr-repo/llm-api:latest
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-secret # kubectl create secret generic openai-secret --from-literal=OPENAI_API_KEY=sk-...
key: OPENAI_API_KEY
- name: REDIS_HOST
value: "redis-service.default.svc.cluster.local"
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
---
# HPA:CPU使用率70%でスケールアウト(コストとのトレードオフを要検討)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: llm-api-server
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
5-3. コスト監視:CloudWatchカスタムメトリクス送信
"""
src/monitoring/cost_tracker.py
APIコールごとにCloudWatchへカスタムメトリクスを送信し、日次コストを可視化する
"""
import boto3
from datetime import datetime
cloudwatch = boto3.client("cloudwatch", region_name="ap-northeast-1")
def record_api_cost(cost_usd: float, model_name: str, tokens: int) -> None:
cloudwatch.put_metric_data(
Namespace="LLM/APIUsage",
MetricData=[
{
"MetricName": "EstimatedCostUSD",
"Dimensions": [{"Name": "Model", "Value": model_name}],
"Value": cost_usd,
"Unit": "None",
"Timestamp": datetime.utcnow()
},
{
"MetricName": "TokensConsumed",
"Dimensions": [{"Name": "Model", "Value": model_name}],
"Value": tokens,
"Unit": "Count",
"Timestamp": datetime.utcnow()
}
]
)
6. メリット・デメリット比較表
コスト削減手法の比較
| 手法 | コスト削減率 | レイテンシへの影響 | 実装コスト | 向いているユースケース | 向かないユースケース |
|---|---|---|---|---|---|
| セマンティックキャッシュ | 最大70% | 改善(キャッシュヒット時) | 中(Redis + Embedding) | FAQ・定型問い合わせ・検索 | 個人化・リアルタイム性重視 |
| モデルルーティング | 最大80% | ほぼなし | 低 | マルチ用途サービス全般 | 全クエリが高精度必須の場合 |
| Batch API | 50%固定 | 大(最大24時間) | 低 | 夜間バッチ・データ加工・評価 | チャット・リアルタイム応答 |
| Prompt Caching | 最大50% | ほぼなし | 最低(設定のみ) | 固定system prompt使用サービス | system promptが毎回変わる場合 |
| 会話履歴要約 | 20〜40% | 軽微 | 低 | 長期チャット・カスタマーサポート | 単発クエリ |
| プロンプト圧縮 | 10〜30% | ほぼなし | 最低 | すべての用途 | なし(常に有効) |
代替手段との比較
| 選択肢 | コスト | 精度 | 運用難易度 | 備考 |
|---|---|---|---|---|
| OpenAI API(最適化済み) | 中〜低 | 高 | 低 | 本記事の手法適用後 |
| AWS Bedrock(Claude / Titan) | 中 | 高 | 低〜中 | AWSネイティブ統合・IAM管理が容易 |
| OSS LLM(Llama 3等)自前ホスト | 低(固定費) | 中〜高 | 高 | GPU/インフラ管理コストが別途発生。EC2 G5インスタンス等が必要 |
| Azure OpenAI Service | 中 | 高 | 低 | Azure環境ならコンプライアンス面で優位。PTU(Provisioned Throughput)でコスト予測が容易 |
現場判断の目安:月間APIコストが$500以下ならOpenAI API最適化が費用対効果最良。$2,000を超えるならAWS BedrockまたはOSSのセルフホストも検討価値があります。
7. よくあるエラーと対策
エラー①:RateLimitError(429)が本番で頻発する
事象:本番トラフィックのピーク時にAPIレスポンスが止まり、以下のエラーが発生する。
openai.RateLimitError: Error code: 429 - {
"error": {
"message": "Rate limit reached for gpt-4o on tokens per min (TPM).
Limit: 30000, Used: 29876, Requested: 1200.",
"type": "tokens",
"code": "rate_limit_exceeded"
}
}
原因:複数のECS/Podインスタンスが同時にAPIを叩いているため、アカウント全体のTPM(Tokens Per Minute)上限に達している。
対策手順:
- OpenAIダッシュボード(platform.openai.com → Settings → Limits)でTPM上限を確認し、Tier昇格申請を行う
- アプリ側にExponential Backoffを実装する:
import time
import random
from openai import RateLimitError
def call_with_retry(func, max_retries: int = 5):
for attempt in range(max_retries):
try:
return func()
except RateLimitError as e:
if attempt == max_retries - 1:
raise
# Exponential backoff: 1s, 2s, 4s, 8s, 16s + jitter
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"Rate limit hit. Waiting {wait:.1f}s (attempt {attempt+1})")
time.sleep(wait)
- CloudWatchでTPM消費量のカスタムメトリクスを監視し、80%到達時点でアラートを受けるよう設定する(上記
cost_tracker.py参照)
エラー②:セマンティックキャッシュが誤ったレスポンスを返す
事象:「今日の天気は?」と「今日のおすすめランチは?」という意味の異なるクエリで、類似度スコアが閾値を超えてしまいキャッシュを誤ヒットし、見当違いの回答が返る。
原因:コサイン類似度のしきい値(SIMILARITY_THRESHOLD)が低すぎるため、意味的に近くない文章でも一致と判定されてしまっている。
対策手順:
cache.pyのSIMILARITY_THRESHOLDを0.92以上(推奨:0.94〜0.96)に引き上げる- ドメイン別にしきい値を分けるよう実装を修正する:
# ドメイン別のしきい値設定(精度が要求される業務系は高めに設定)
DOMAIN_THRESHOLDS = {
"medical": 0.97, # 医療・法律系:誤キャッシュは致命的
"general": 0.93, # 一般FAQ
"search": 0.90, # 検索補助系:多少の揺れは許容
}
- キャッシュヒット時に必ず元のクエリと取得クエリをログに記録し、週次でサンプリングチェックを行う体制を整える
エラー③:会話履歴の要約で文脈が失われ回答品質が低下する
事象:チャットセッションが長くなると履歴が要約され、それ以降のユーザーへの回答が突然的外れになる。ログを確認すると以下が出力されている。
[HISTORY TRIMMED] 12件を要約しました
# この直後のレスポンス精度が著しく低下
原因:MAX_HISTORY_TOKENSが低すぎるために要約が頻発し、かつgpt-4o-miniでの要約が重要な文脈情報(ユーザーの名前・前提条件・数値など)を落としてしまっている。
対策手順:
MAX_HISTORY_TOKENSを用途に応じて調整する(カスタマーサポートなら4000〜6000推奨)- 要約プロンプトを改善し、構造化情報を保持するよう指示する:
SUMMARY_SYSTEM_PROMPT = """
以下の会話を要約してください。必ず以下の情報を保持してください:
- ユーザーが提示した具体的な数値・固有名詞・制約条件
- 確定事項と未解決事項の区別
- 次のアクション(もしあれば)
出力は箇条書き形式で200字以内に収めてください。
"""
- 要約後の最初のレスポンスを品質モニタリング対象としてフラグを立て、定期的に人手で評価するパイプラインを組む
エラー④:Batch APIのジョブがfailedになりサイレントに失敗する
事象:Batch APIを投入したが24時間後に確認するとステータスがfailedになっており、出力ファイルが空になっている。
batch = client.batches.retrieve("batch_abc123")
print(batch.status) # -> "failed"
print(batch.errors) # -> {"data": [{"code": "invalid_json_line", "line": 42}]}
原因:入力JSONLファイルの42行目に不正なJSON(例:日本語テキスト内の制御文字、またはmax_tokensが未設定)が含まれているため、バッチ全体が失敗扱いになっている。
対策手順:
- Batch投入前に入力ファイルのバリデーションを実施する:
import json
def validate_batch_file(filepath: str) -> bool:
with open(filepath, "r", encoding="utf-8") as f:
for i, line in enumerate(f, 1):
try:
obj = json.loads(line.strip())
assert "custom_id" in obj
assert "body" in obj
assert "max_tokens" in obj["body"] # 必須フィールドチェック
except Exception as e:
print(f"Line {i} is invalid: {e}")
return False
return True
- バッチ完了後は必ず
batch.request_countsでfailed件数を確認し、アラートに組み込む - 大量データは1バッチ50,000件以内に分割して投入する(公式上限:50,000 requests / 200MB)
8. まとめ:実務での使い方の整理
OpenAI APIのコスト最適化は「一度設定すれば終わり」ではなく、継続的なモニタリングと改善が前提です。現場での実践ポイントをまとめます。
立ち上げフェーズ(〜1ヶ月目)
- まずモデルルーティングとプロンプト圧縮を導入(工数小・効果大)
- Prompt Cachingを有効化(system promptが固定であれば最低限の改修で50%削減)
- CloudWatchまたはDatadogで日次コスト監視ダッシュボードを構築する
安定運用フェーズ(2〜3ヶ月目)
- セマンティックキャッシュを本番投入し、キャッシュヒット率を週次でレビューする
- 非リアルタイム処理をBatch APIへ移行(夜間バッチ、データラベリングなど)
- 会話型サービスには履歴要約管理を適用する
コスト最適化の現実
月間コストが$500未満の段階では、過度な最適化よりモデル選定の見直しが最もROIが高いです。全クエリにgpt-4oを使っているなら、まずgpt-4o miniへの切り替えを検討してください。それだけで多くの場合、コストは劇的に下がります。$2,000を超え始めたら、AWS BedrockやセルフホストLLMとの比較検討も視野に入れましょう。
本記事のコードはすべて本番環境での利用を想定しており、エラーハンドリング・ロギング・モニタリングまで含めた形で設計しています。まずはrouter.pyとprompt_utils.pyだけでも既存プロジェクトに組み込んでみてください。


コメント