LangChainを使わないLLMエージェントの作り方(AWS対応・実務レベル解説)
目次
1. 結論(最初に答え)
LangChainを使わずにLLMエージェントを構築する最適解は、「OpenAI API + 軽量オーケストレーター(FastAPI) + 自前ツール実装」です。
理由は以下です。
- 依存ライブラリが少なく障害点が減る
- AWS / Kubernetesにそのまま載せやすい
- コスト・遅延・挙動を完全制御できる
つまり「フレームワークに頼る」のではなく、必要な部分だけを部品として組み立てる構成が実務では最も安定します。
2. そもそもLLMエージェントとは何か
LLMエージェントとは、単なるチャットではなく「目的達成のためにツールを使い分けるAI」です。
例:
- ユーザー質問 → DB検索
- API呼び出し → AWS情報取得
- 計算 → Python実行
LangChainなしでも、これらはすべて「ルーティング設計」で実現できます。
3. 仕組み解説(アーキテクチャ)
基本構成は以下です。
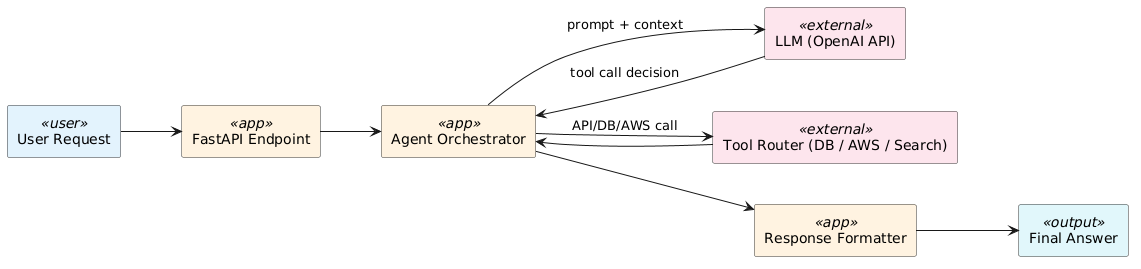
ポイントは「LLMに全部やらせない」ことです。
意思決定(どのツールを使うか)と実行を分離します。
4. 実装手順(ステップ形式)
■使用技術
- Python 3.11
- FastAPI
- OpenAI API
- boto3(AWS連携)
■ディレクトリ構成
llm-agent/ ├── app/ │ ├── main.py │ ├── agent.py │ ├── tools.py │ └── config.py ├── requirements.txt └── Dockerfile
■実装コード
app/main.py
from fastapi import FastAPI
from app.agent import run_agent
app = FastAPI()
@app.get("/ask")
def ask(query: str):
return {"result": run_agent(query)}app/agent.py
import openai
from app.tools import search_db, call_aws
def run_agent(query: str):
messages = [
{"role": "system", "content": "You are a helpful agent that can use tools."},
{"role": "user", "content": query}
]
response = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=messages,
functions=[
{
"name": "search_db",
"description": "Search internal database"
},
{
"name": "call_aws",
"description": "Fetch AWS resources"
}
]
)
return response["choices"][0]["message"]["content"]app/agent.py
import boto3
import requests
from app.config import settings
# -----------------------
# 1. 内部DB検索ツール
# -----------------------
def search_db(query: str):
"""
例: 社内ナレッジ検索(RDS / OpenSearch想定)
"""
# ダミー実装(本番はSQL or OpenSearch)
return {
"query": query,
"result": "dummy result from internal DB"
}
# -----------------------
# 2. AWS連携ツール
# -----------------------
def call_aws(service: str):
"""
例: AWSリソース取得(Cost Explorer / EC2など)
"""
client = boto3.client(service, region_name=settings.AWS_REGION)
if service == "ec2":
response = client.describe_instances()
return response
if service == "ce":
# Cost Explorer例(簡略)
return {"cost": "100 USD"}
return {"error": "unsupported service"}
# -----------------------
# 3. 外部API連携(例:Slack通知)
# -----------------------
def notify_slack(message: str):
webhook_url = settings.SLACK_WEBHOOK_URL
response = requests.post(webhook_url, json={
"text": message
})
return {"status": response.status_code}app/config.py
import os
class Settings:
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
AWS_REGION = os.getenv("AWS_REGION", "ap-northeast-1")
DB_ENDPOINT = os.getenv("DB_ENDPOINT")
REDIS_HOST = os.getenv("REDIS_HOST", "localhost")
REDIS_PORT = int(os.getenv("REDIS_PORT", 6379))
MODEL_NAME = os.getenv("MODEL_NAME", "gpt-4o-mini")
settings = Settings()■起動方法
pip install -r requirements.txt
uvicorn app.main:app --host 0.0.0.0 --port 8000アクセス:
http://localhost:8000/ask?query=hello
5. 実務ユースケース(AWS / Kubernetes)
ケース:AWSコスト分析エージェント
- CloudWatch + Cost Explorer API連携
- LLMが異常検知クエリを生成
- 結果をSlack通知
Kubernetes構成
- FastAPI → Deployment
- LLM API → 外部通信(VPC egress制御)
- Redis → キャッシュ層
ポイントは「LLMをクラスタ内に閉じない」ことです。コストとレイテンシが悪化します。 —
6. メリット・デメリット
| 項目 | LangChainなし | LangChainあり |
|---|---|---|
| 制御性 | 高い(完全設計可能) | ブラックボックス化しやすい |
| 学習コスト | 低〜中 | 中〜高 |
| 運用性 | 高(AWS/K8s親和性◎) | 依存関係が増える |
| 開発速度 | 初期は遅い | 初期は速い |
7. よくある失敗と対策
事象1:LLMがツールを呼ばない
原因:プロンプトにツール使用条件が不足しているため、LLMが「直接回答」してしまう。
Error: Tool was never called. Model responded directly.
対策:
- system promptに「必ずツール優先」を明記
- function calling強制フラグを利用
事象2:AWS APIがタイムアウト
原因:LLM経由で同期処理しているため、API応答待ちで遅延が発生。
対策:
- 非同期化(async boto3 + queue)
- SQS経由でバッチ処理
事象3:コスト爆発
原因:全リクエストをGPT-4系で処理しているため。
対策:
- 軽量モデル(gpt-4o-mini)へルーティング
- キャッシュ(Redis)導入
8. 代替手段の比較
- LangChain:開発速度重視(ただしブラックボックス)
- LlamaIndex:RAG特化
- 自前実装(今回):運用・コスト最適化に最強
本番運用では「自前実装 + 最小ライブラリ構成」が最も安定します。
9. まとめ
LangChainを使わないLLMエージェント構築は、シンプルな構成ほど本番に強いという原則に従います。
- FastAPIでAPI層を作る
- LLMは意思決定だけ担当
- ツール実行は完全に分離
結果として、AWS・Kubernetes環境でもスケーラブルでコスト最適なAIシステムを構築できます。

コメント