
はじめに
「RAGってよく聞くけど、実際どうやって作るの?」「ベクトル検索とか難しそうで手が出せない…」
そんな状態からでも、ローカル環境だけで“動くRAG”を作れる構成をこの記事では紹介します。
本記事では、トヨタやソニーの決算PDFを使いながら、
PDFを読み込んで → AIが検索できる形に変換し → チャット形式で質問できる
という一連の流れを、FAISS × S3 × Python × Streamlitで構築していきます。やっていることはシンプルです。
「文章を細かく分けて → 数値化して → 似ているものを探して → AIに答えさせる」
これを一つずつ積み上げていくだけです。難しい理論は後回しでOKです。
まずは「動くもの」を作りながら、RAGの全体像をつかんでいきましょう。
全体構成
まずは全体の構成を「アーキテクチャ構成図」と「フォルダ構成」で示します。
手順を実施するうえで、何をしているのかを把握しながら進めることが大事だと思いますので、この図を振り返りながら進めていただくと理解が深まると思います。
アーキテクチャ構成図

フォルダ構成
project-root/
├── app/
│ └── app.py # Streamlitアプリ本体(質問→検索→回答)
│
├── scripts/
│ ├── extract_text.py # PDF→テキスト抽出
│ ├── chunk.py # テキスト分割(チャンク化)
│ ├── embed.py # ベクトル化&FAISSインデックス生成
│ └── __pycache__/ # (自動生成)Pythonキャッシュ
│ └── chunk.cpython-39.pyc
│
├── data/
│ ├── texts.txt # 抽出された生テキスト
│ ├── texts.npy # チャンク化済みテキスト
│ ├── meta.npy # メタ情報(会社・ファイル紐付け)
│ ├── index.faiss # ベクトル検索インデックス(コア)
│ │
│ ├── toyota/ # トヨタ決算PDF
│ │ ├── 2026_1q_summary_jp.pdf
│ │ ├── 2026_2q_summary_jp.pdf
│ │ └── 2026_3q_summary_jp.pdf
│ │
│ └── sony/ # ソニー決算PDF
│ ├── 25q1_sony.pdf
│ ├── 25q2_sony.pdf
│ └── 25q3_sony.pdf
│
├── metadata/
│ └── files.csv # PDF管理データ(company, yearなど)
│
└── requirements.txt # 依存ライブラリ一覧前提(環境)
・AlmaLinux9
(本記事ではAlmaLinux9で実施してるが、自身の環境に合わせて読み替えて実施可能です。コマンドはAlmaLinuxベースで記載しているので、AlmaLinuxをインストールするほうが構築はしやすいかと思います。)
・AWS アカウント
・OPEN AIのAPIキー
事前準備
開発ツールインストール
AlmaLinux9を起動後以下のコマンドを実行し、必要なツールをインストールする。
sudo dnf update -y
sudo dnf install epel-release -y
sudo dnf install gcc openssl-devel bzip2-devel libffi-devel zlib-devel wget make -y
sudo dnf install vi -yPython3.12をインストール
以下のコマンドを実行し、Python3.12をインストールする。
※AlmaLinux9にはpyhon3.9がインストールされるが、今回実施する内容では3.10以上のバージョンが推奨であるため、ここでPython3.12をインストールしています。なお、ビルドしてインストールしているので少し時間がかかります。
wget https://www.python.org/ftp/python/3.12.0/Python-3.12.0.tar.xz
tar -xf Python-3.12.0.tar.xz
cd Python-3.12.0
./configure --enable-optimizations
make -j $(nproc)
sudo make altinstallAWS CLIインストール
以下のコマンドを実行し、AWS CLIをインストールする。
(このインストールが完了するとAWSのコマンドを実行できるようになります。)
pip install awscliAWS Configure設定
以下のコマンドを実行し、認証情報を入力する。
aws configure・AWS Access Key ID:{自身のAWSアカウントのアクセスキー}
・AWS Secret Access Key:{自身のAWSアカウントのシークレットキー}
・region: ap-northeast-1
・output: json
ローカル環境準備
以下のコマンドを実行し、作成した仮想環境を有効化する。
有効化すると、ターミナルの先頭に (venv)と表示され、 以降の python や pip install はこの環境専用になる。
cd ~
python -m venv venv
source venv/bin/activateディレクトリ作成
以下のコマンドを実行し、RAG構築・利用に必要なディレクトリを作成する。
mkdir -p ~/project-root/app
mkdir -p ~/project-root/data/toyota
mkdir -p ~/project-root/data/sony
mkdir -p ~/project-root/scripts
mkdir -p ~/project-root/faiss_index
cd project-rootPDF配置
トヨタやソニーなど、自身が利用したいいpdf情報を取得し、~/project-root/dataに配置する。
(本記事ではソニーとトヨタの決算資料をサンプルとして配置している。)
~/project-root/data/sony/25q1_sony.pdf
~/project-root/data/sony/25q2_sony.pdf
~/project-root/data/sony/25q3_sony.pdf
~/project-root/data/toyota/2026_1q_summary_jp.pdf
~/project-root/data/toyota/2026_2q_summary_jp.pdf
~/project-root/data/toyota/2026_3q_summary_jp.pdfS3バケット作成&PDFアップロード
S3バケットを作成してPDFをアップロードする。
aws s3 mb s3://rag-financial-data-12345
aws s3 cp ~/project-root/data/ s3://rag-financial-data-12345/data/ --recursiveメタデータCSV作成
metadata用ディレクトリを作成し、CSVファイルを作成する。
mkdir -p ~/project-root/metadata
vi ~/project-root/metadata/files.csvファイル内容↓
company,year,quarter,s3_path
toyota,2023,Q1,s3://rag-financial-data-12345/data/toyota/2026_1q_summary_jp.pdf
toyota,2023,Q2,s3://rag-financial-data-12345/data/toyota/2026_2q_summary_jp.pdf
toyota,2023,Q3,s3://rag-financial-data-12345/data/toyota/2026_3q_summary_jp.pdf
sony,2023,Q1,s3://rag-financial-data-12345/data/sony/25q1_sony.pdf
sony,2023,Q2,s3://rag-financial-data-12345/data/sony/25q2_sony.pdf
sony,2023,Q3,s3://rag-financial-data-12345/data/sony/25q3_sony.pdf以下のコマンドを実行し、S3アップロードする。
aws s3 cp ~/project-root/metadata/files.csv s3://rag-financial-data-12345/metadata/files.csvrequirements作成
依存ライブラリを保持するファイルである「requirements.txt」を作成する。
vi ~/project-root/requirements.txtファイル内容↓
boto3
pandas
PyPDF2
faiss-cpu
openai
Tqdm
pdfplumber以下のコマンドを実行し、インストールを実施する。
pip install -r ~/project-root/requirements.txtpython作成
以下のpythonファイルを作成する。
~/project-root/scripts/extract_text.py
import os
import pdfplumber
DATA_DIR = "data"
OUTPUT_FILE = "data/texts.txt"
def clean_text(text: str) -> str:
if not text:
return ""
return (
text.replace("\n", " ")
.replace("\r", " ")
.replace("\t", " ")
.strip()
)
def run():
with open(OUTPUT_FILE, "w", encoding="utf-8") as out:
for company in os.listdir(DATA_DIR):
cpath = os.path.join(DATA_DIR, company)
# ディレクトリのみ処理(超重要)
if not os.path.isdir(cpath):
continue
for file in os.listdir(cpath):
if not file.endswith(".pdf"):
continue
path = os.path.join(cpath, file)
print(f"Processing: {path}")
try:
with pdfplumber.open(path) as pdf:
for page in pdf.pages:
text = page.extract_text()
if text:
text = clean_text(text)
if text:
out.write(f"{company}|{file}|{text}\n")
except Exception as e:
print(f"Error processing {path}: {e}")
print("✅ テキスト抽出完了")
if __name__ == "__main__":
run()~/project-root/scripts/chunk.py
CHUNK_SIZE = 500
def chunk_text(text):
words = text.split()
for i in range(0, len(words), CHUNK_SIZE):
yield " ".join(words[i:i+CHUNK_SIZE])~/project-root/scripts/embed.py
import faiss
import numpy as np
from openai import OpenAI
from chunk import chunk_text
client = OpenAI()
texts = []
metas = []
with open("data/texts.txt", encoding="utf-8") as f:
for line in f:
company, file, text = line.strip().split("|", 2)
for chunk in chunk_text(text):
texts.append(chunk)
metas.append((company, file))
embeddings = []
for t in texts:
res = client.embeddings.create(
model="text-embedding-3-small",
input=t
)
embeddings.append(res.data[0].embedding)
embeddings = np.array(embeddings).astype("float32")
index = faiss.IndexFlatL2(len(embeddings[0]))
index.add(embeddings)
faiss.write_index(index, "data/index.faiss")
np.save("data/meta.npy", metas)
np.save("data/texts.npy", texts)~/project-root/app/app.py
for m in history:
messages.append(m)
messages.append({
"role": "user",
"content": f"""
質問:
{q}
参考資料:
{context}
"""
})
res = client.chat.completions.create(
model="gpt-4.1-mini",
messages=messages
)
return res.choices[0].message.content, context_chunks
# ===== 過去メッセージ表示 =====
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.write(msg["content"])
# ===== 入力欄 =====
if prompt := st.chat_input("質問してください(例:トヨタの2023年Q1の営業利益は?)"):
# ユーザー入力表示
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# AI応答
with st.chat_message("assistant"):
with st.spinner("分析中..."):
answer, context_chunks = search(prompt)
st.write(answer)
# 参考資料(折りたたみ)
with st.expander("📄 参考にしたテキスト"):
for i, chunk in enumerate(context_chunks):
st.markdown(f"**Chunk {i+1}**")
st.write(chunk)
# 履歴に追加
st.session_state.messages.append({"role": "assistant", "content": answer})OPEN AIのAPIキー設定
今回のRAG構成では、OPEN AIのAPI機能を利用するため、その認証としてAPIキーが必要となる。
以下の手順でOPEN AIのAPIキーを設定する。
nano ~/.bashrcexport OPENAI_API_KEY="sk-xxxxxxx"ctl + O ,ctl + Xで保存して終了
source ~/.bashrc
echo $OPENAI_API_KEY※OPEN AIのAPIキー取得方法はインターネット検索で出てくると思いますのでお手数ですがそちらを参照ください。
実行
作成したpythonコードを実行する。
python ~/project-root/scripts/extract_text.py
python ~/project-root/scripts/embed.py今回の構成ではstreamlitを用いてChatUIを構築するために「streamlit」をインストールしてapp.pyを起動する。
pip install streamlit
streamlit run ~/project-root/app/app.pyapp.pyを起動すると以下のような画面が現れるが、無視してEnterを押下する。

アクセス&利用確認
http://localhost:8501へアクセスすると以下のような画面が表示される。
得たい質問を投げかけると、AIが回答してくれる。
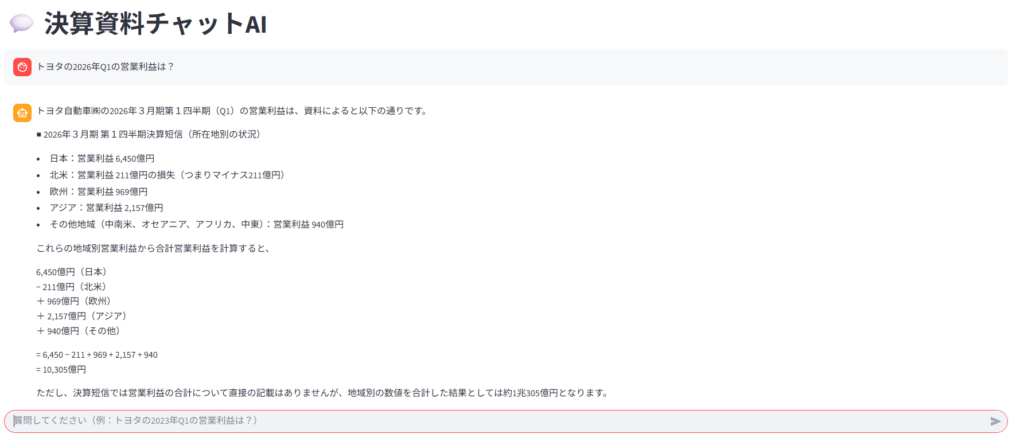
以上でRAG構築完了となります。
おわりに
今回は、FAISSとS3を組み合わせたシンプルなRAG構成を、ローカル環境から構築しました。
ポイントは3つです。
・ローカルで完結できるシンプルな構成
・実データ(決算PDF)を使ったリアルなユースケース
・UIまで含めて「実際に使える形」まで持っていくこと
この構成の良いところは、無理なく段階的に拡張できることです。
たとえば、Athenaでメタデータ検索を強化したり、S3中心の構成に寄せていけば、そのまま実務レベルにもスケールできます。RAGは難しく見えますが、分解するとやっていることはシンプルです。一度手を動かしてしまえば、理解のスピードは一気に上がります。ぜひこの構成をベースに、「自分のデータで検索できるAI」を作ってみてください。


コメント