
はじめに
Kubernetesを使い始めてしばらくすると、「このクラスター、ちゃんと見えているのか?」という不安に直面します。Podの状態やリソース使用量、異常の兆候——それらを可視化するためにPrometheusやGrafanaが必要だと分かっていても、「どう組み合わせて構築するのか」が分からず、手が止まってしまうケースは少なくありません。
本記事は、Kubernetesをある程度触ったことがあり、Terraformにも軽く触れたことがあるものの、「監視基盤はこれから」という方を対象にしています。Rancher DesktopとAlmaLinuxを使い、ローカル環境上にPrometheusとGrafanaをTerraformで構築することで、監視基盤の全体像を“再現性のある形”で理解することを目的としています。
また、Alertmanagerをあえて無効化するなど、検証に適した軽量構成にすることで、無理なく手元で試せる形にしています。単なる手順のなぞりではなく、「実務でどう繋がるのか」を意識しながら読み進めてもらえればと思います。
全体構成
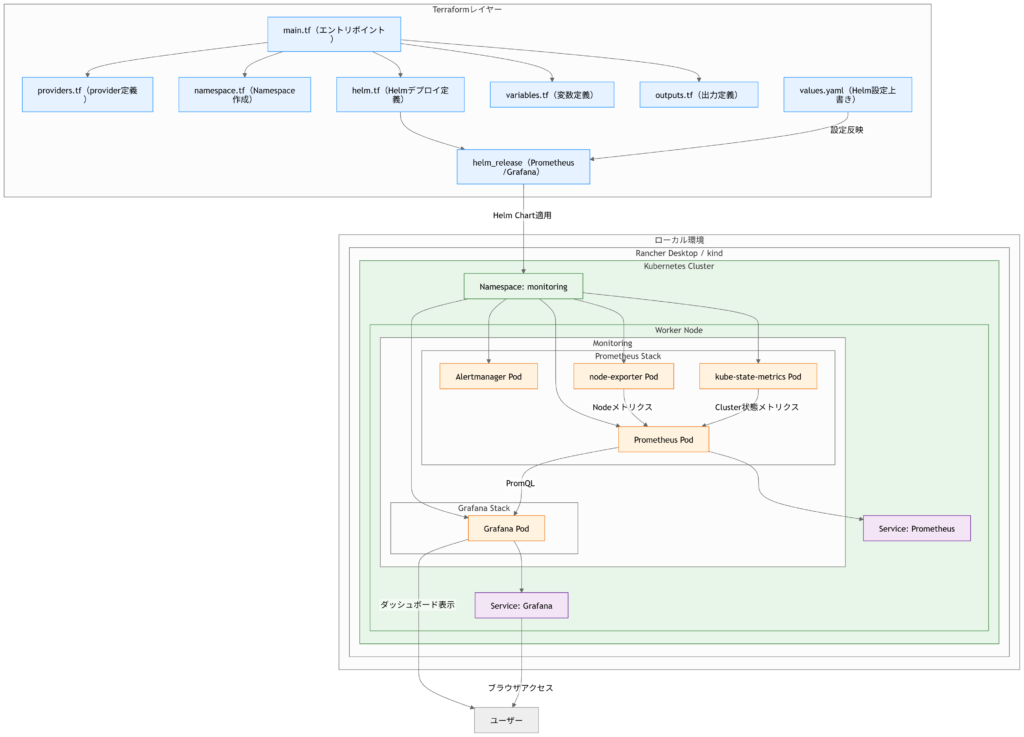
前提環境
・AlmaLinux9がインストールされている
・Rancher Desktopがインストールされている
手順
kubectl確認
AlmaLinuxを起動し、以下のコマンドを実行。kubectlコマンドが利用できることを確認する。
kubectl versionディレクトリ作成
下記のようなディレクトリ構成でファイルを作成していく。

以下のコマンドを実行し、ディレクトリを作成する。
mkdir -p ~/terraform-k8s-monitoring
cd ~/terraform-k8s-monitoring以下のコマンドを実行し、ファイルを作成する。
touch main.tf
touch providers.tf
touch namespace.tf
touch helm.tf
touch values.yaml
touch variables.tf
touch outputs.tf各ファイルの内容を記入していく。(下記の内容をコピー&ペーストする。)
main.tf
terraform {
required_version = ">= 1.3.0"
}providers.tf
terraform {
required_providers {
kubernetes = {
source = "hashicorp/kubernetes"
version = ">= 2.20.0"
}
helm = {
source = "hashicorp/helm"
version = ">= 2.10.0"
}
}
}
provider "kubernetes" {
config_path = "~/.kube/config"
}
provider "helm" {
kubernetes = {
config_path = "~/.kube/config"
}
}variables.tf
variable "monitoring_namespace" {
type = string
default = "monitoring"
description = "Namespace where monitoring stack will be deployed."
}
variable "kube_prometheus_stack_release_name" {
type = string
default = "kube-prometheus-stack"
description = "Helm release name for kube-prometheus-stack."
}
variable "kube_prometheus_stack_chart_version" {
type = string
# 安定しているバージョンを指定(必要に応じて更新)
default = "65.5.1"
description = "Chart version of kube-prometheus-stack."
}namespace.tf
resource "kubernetes_namespace" "monitoring" {
metadata {
name = var.monitoring_namespace
}
}helm.tf
resource "helm_release" "kube_prometheus_stack" {
name = var.kube_prometheus_stack_release_name
namespace = var.monitoring_namespace
chart = "kube-prometheus-stack"
repository = "https://prometheus-community.github.io/helm-charts"
version = var.kube_prometheus_stack_chart_version
// namespace が存在しないと失敗するので依存関係を明示
depends_on = [
kubernetes_namespace.monitoring
]
values = [
file("${path.module}/values.yaml")
]
}outputs.tf
output "grafana_service_name" {
description = "Grafana Service name in the monitoring namespace."
value = "kube-prometheus-stack-grafana"
}
output "prometheus_service_name" {
description = "Prometheus Service name in the monitoring namespace."
value = "kube-prometheus-stack-prometheus"
}
output "monitoring_namespace" {
description = "Namespace where monitoring stack is deployed."
value = var.monitoring_namespace
}values.yaml
# ローカル環境向けに、できるだけ軽量にした kube-prometheus-stack 設定
# Alertmanager は今回は無効化(軽量化のため)
alertmanager:
enabled: false
# Prometheus の設定
prometheus:
enabled: true
service:
type: ClusterIP
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
retention: "12h"
# Grafana の設定
grafana:
enabled: true
service:
type: ClusterIP
port: 80
adminUser: "admin"
adminPassword: "admin"
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
# kube-state-metrics(Kubernetes オブジェクトの状態メトリクス)
kubeStateMetrics:
enabled: true
# Node Exporter(ノードの CPU / メモリ / ディスクなど)
prometheus-node-exporter:
enabled: true
resources:
requests:
cpu: "50m"
memory: "64Mi"
limits:
cpu: "200m"
memory: "128Mi"
# kube-proxy / kubelet / apiserver などのメトリクスも有効化(デフォルトで十分)
kubeApiServer:
enabled: true
kubeControllerManager:
enabled: true
kubeScheduler:
enabled: true
kubeProxy:
enabled: true
# etcd は Rancher Desktop の構成によっては不要だが、基本はデフォルトのまま
kubeEtcd:
enabled: trueTeraform適用
以下のコマンドを実行し、初期化と適用を行う
terraform init
terraform plan
terraform apply起動確認
以下のコマンドを実行し、podの起動確認を行う
kubectl get pods -n monitoring起動が成功していると、以下のような状態となっているはずです。失敗している場合は、各tfファイルやyamlファイルのコピー&ペーストに失敗している可能性もあるので、ご自身のファイルをご確認ください。
NAME READY STATUS RESTARTS AGE
kube-prometheus-stack-grafana-78c7ddc69d-bsgsd 3/3 Running 0 3m14s
kube-prometheus-stack-kube-state-metrics-59c7849b88-q6vrw 1/1 Running 0 3m14s
kube-prometheus-stack-operator-6bb7f559d8-jqb4f 1/1 Running 0 3m14s
kube-prometheus-stack-prometheus-node-exporter-sm4sv 1/1 Running 0 3m14s
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 2m56sポートフォワード
kubernetes環境にpodを立ち上げただけではアクセスすることができないため、以下のコマンドを実行し、ポートフォワードする。
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80Grafanaへアクセス
localhost:3000でアクセスするとGrafanaの画面が表示されるため、以下の情報でログインする。
Username: admin
Password: admin
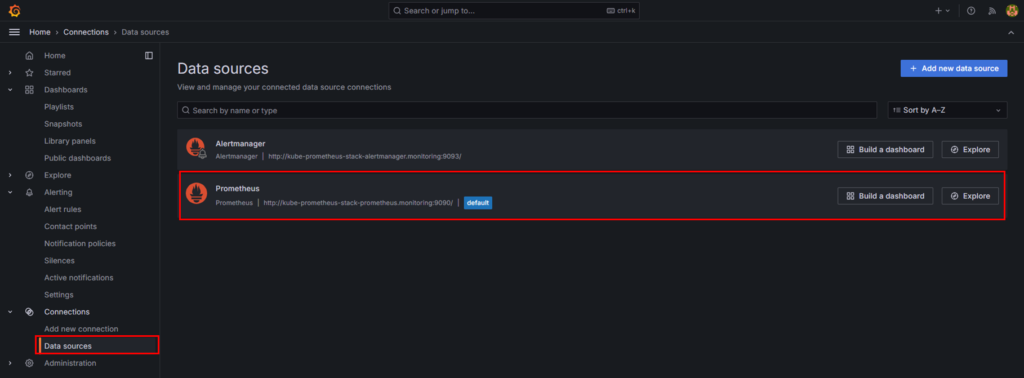
Connection > Data sourceを選択し、Prometheusが表示されていることを確認。
【参考】Grafanaの使い方
試しにpodを1つ新たに作成して、メモリ、CPU状況をGrafanaで確認してみましょう。
クエリ確認
Grafanaをひらき、ExploreからテストAlert用クエリを実行し、グラフが出ていることを確認します。
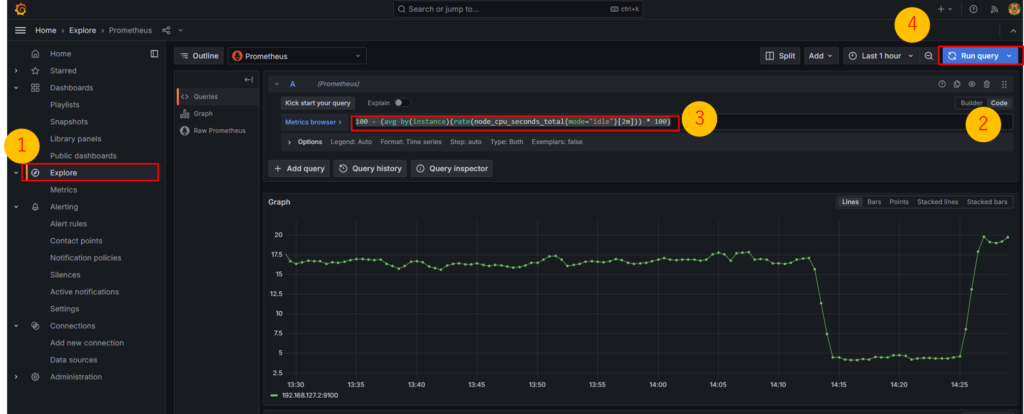
↓クエリ
100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100)アラート設定
Alerting > Alert rulesより、先ほどのクエリを入力しSaveします。
※必須項目がいくつかあるので適当にしてsaveが通ればOKです。
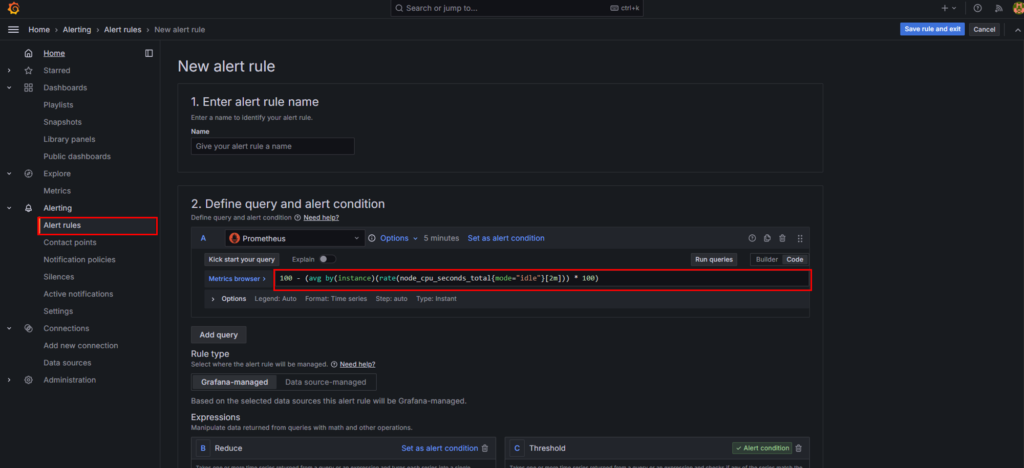
負荷をかけるpod起動
AlmaLinuxで以下のコマンドを実行し、負荷をかけるpodを起動します。
kubectl run cpu-burn --image=busybox --restart=Never -- sh -c "while true; do :; done"確認
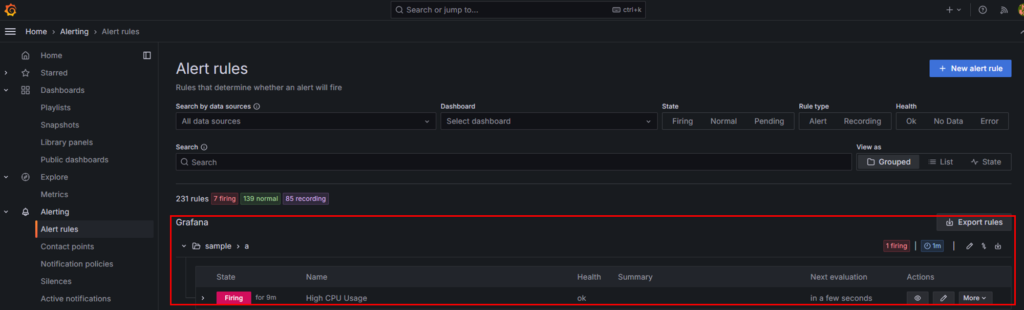
少しまつと以下のように作成したAlertが「Firing」表示されていることがわかります。
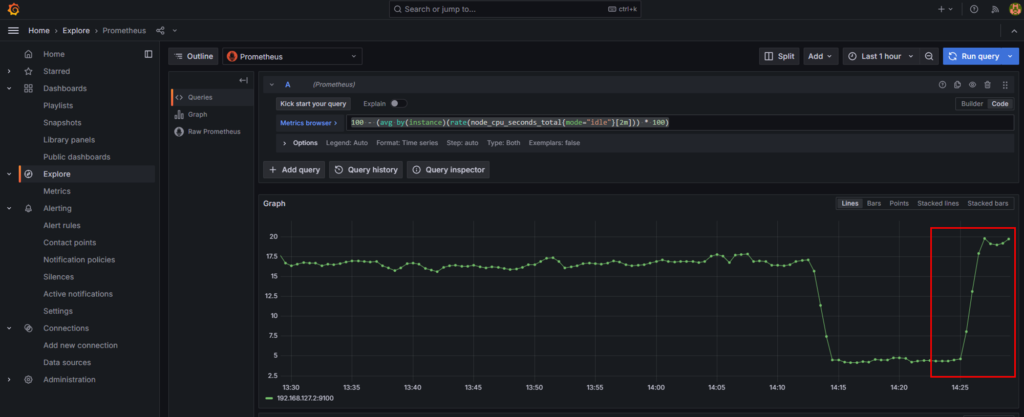
先ほどのクエリをExploreから実行してみるとCPUの負荷が増えていることが確認できます。
以上で手順終了です。
おわりに
ここまでの手順を通して、Terraformを使ってKubernetes上に監視基盤を構築し、その動きをローカルで確認できる状態が整ったはずです。一度自分の手で再現してみると、Prometheusがどのようにメトリクスを収集し、Grafanaでどのように可視化されるのか、その流れが自然と理解できるようになります。
監視は後回しにされがちな領域ですが、実務では非常に重要な基盤の一つです。今回の構成をベースに、Alertmanagerの導入や通知設計、クラウド環境への展開などへ発展させていくことで、より実践的なスキルに繋がっていきます。
この記事が、監視基盤への最初の一歩として役に立てば嬉しいです。今後も、実務に活かせる検証や構築手順をベースに発信していくので、引き続き参考にしてもらえればと思います。

コメント